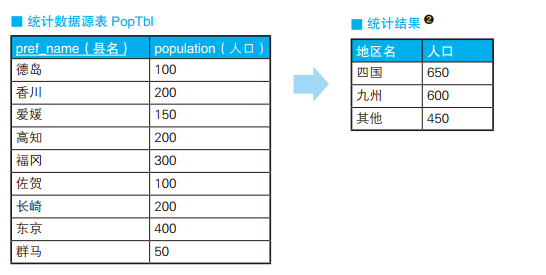
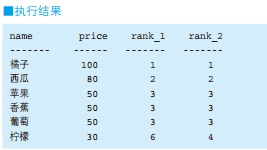
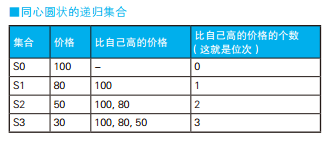
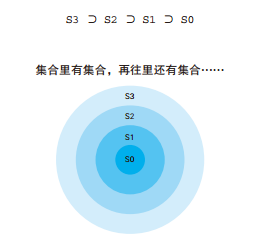
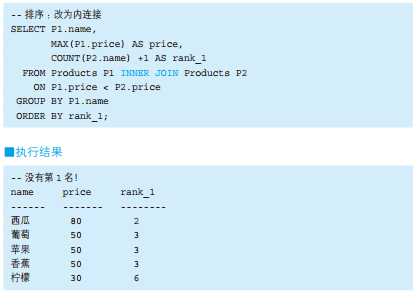
-- 按人口数量等级划分都道府县 SELECTCASEWHEN population <100THEN'01' WHEN population >=100AND population <200THEN'02' WHEN population >=200AND population <300THEN'03' WHEN population >=300THEN'04' ELSENULLENDAS pop_class, COUNT(*) AS cnt FROM PopTbl GROUPBYCASEWHEN population <100THEN'01' WHEN population >=100AND population <200THEN'02' WHEN population >=200AND population <300THEN'03' WHEN population >=300THEN'04' ELSENULLEND;
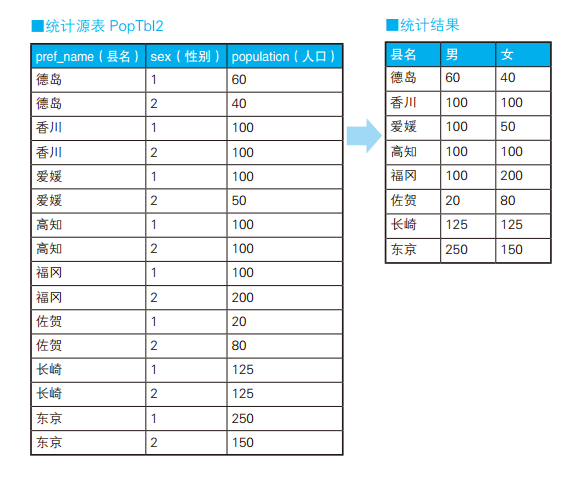
-- 这种方式可以实现列转行 SELECT pref_name, -- 男性人口 SUM(CASEWHEN sex ='1'THEN population ELSE0END) AS cnt_m, -- 女性人口 SUM(CASEWHEN sex ='2'THEN population ELSE0END) AS cnt_f FROM PopTbl2 GROUPBY pref_name;
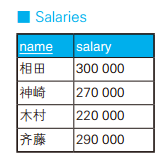
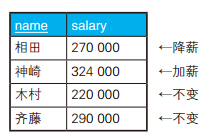
-- 用 CASE 表达式写正确的更新操作 UPDATE Salaries SET salary =CASEWHEN salary >=300000 THEN salary *0.9 WHEN salary >=250000AND salary <280000 THEN salary *1.2 ELSE salary END
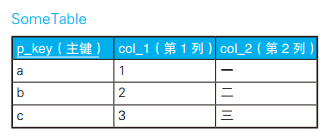
用 CASE 表达式调换主键 a, b 的值
1 2 3 4 5 6 7 8
-- 用 CASE 表达式调换主键值 UPDATE SomeTable SET p_key =CASEWHEN p_key ='a' THEN'b' WHEN p_key ='b' THEN'a' ELSE p_key END WHERE p_key IN ('a', 'b');
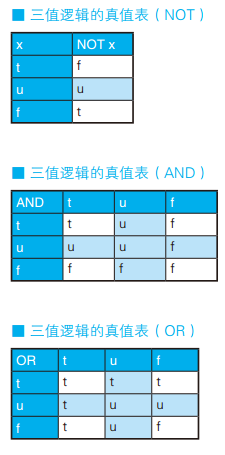
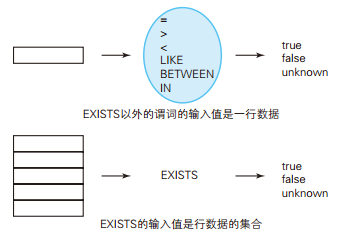
如下这个 CASE 表达式一定不会返回 ×。这是因为,第二个 WHEN 子句是 col_1 = NULL 的缩写形式。正如大家所知,这个式子的真值永远是 unknown。而且 CASE 表达式的判断方法与 WHERE 子句一样,只认可真值为 true 的条件。 需要将 WHEN NULL 修改为 WHEN IS NULL。
1 2 3 4 5
--col_1 为 1 时返回○、为 NULL 时返回 × 的 CASE 表达式? CASE col_1 WHEN1THEN'○' WHENNULLTHEN'×' END
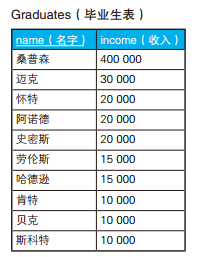
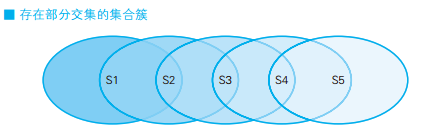
-- 求众数的SQL语句(1):使用谓词 SELECT income, COUNT(*) AS cnt FROM Graduates GROUPBY income HAVINGCOUNT(*) >=ALL ( SELECTCOUNT(*) FROM Graduates GROUPBY income);
income cnt ------ --- 100003 200003
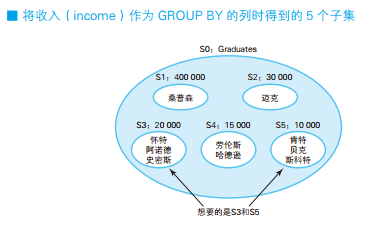
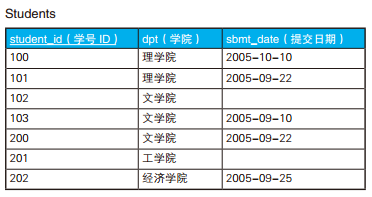
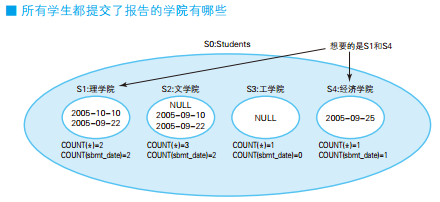
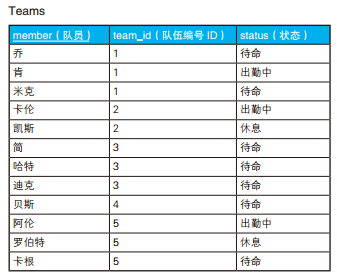
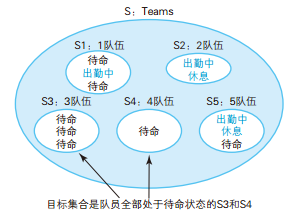
GROUP BY 子句的作用是根据最初的集合生成若干个子集。因此,将收入(income)作为 GROUP BY 的列时,将得到 S1 ~ S5 这样 5 个子集。这几个子集里,元素数最多的是 S3 和 S5,都是 3 个元素,因此查询的结果也是这 2 个集合。
ALL 谓词用于 NULL 或空集时会出现问题,可以用极值函数来代替。这里要求的是元素数最多的集合,因此可以用 MAX 函数。
1 2 3 4 5 6 7 8
-- 求众数的SQL语句(2):使用极值函数 SELECT income, COUNT(*) AS cnt FROM Graduates GROUPBY income HAVINGCOUNT(*) >= ( SELECTMAX(cnt) FROM ( SELECTCOUNT(*) AS cnt FROM Graduates GROUPBY income ) TMP ) ;
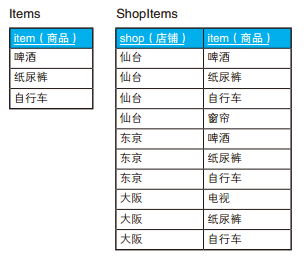
-- 查询啤酒、纸尿裤和自行车同时在库的店铺:正确的SQL语句 SELECT SI.shop FROM ShopItems SI, Items I WHERE SI.item = I.item GROUPBY SI.shop HAVINGCOUNT(SI.item) = (SELECTCOUNT(item) FROM Items);
shop ---- 仙台 东京
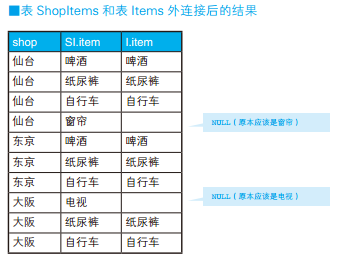
如果把 HAVING 子句改成 HAVING COUNT (SI.item) =COUNT (I.item),结果就不对了。如果使用这个条件,仙台、东京、大阪这 3 个店铺都会被选中。这是因为,受到连接操作的影响, COUNT (I.item) 的值和表 Items 原本的行数不一样了。
1 2 3 4 5 6 7 8 9 10 11
-- COUNT(I.item)的值已经不一定是3了 SELECT SI.shop, COUNT(SI.item), COUNT(I.item) FROM ShopItems SI, Items I WHERE SI.item = I.item GROUPBY SI.shop;
-- 用外连接进行关系除法运算:差集的应用 SELECTDISTINCT shop FROM ShopItems SI1 WHERENOTEXISTS (SELECT I.item FROM Items I LEFTOUTERJOIN ShopItems SI2 ON SI1.shop = SI2.shop AND I.item = SI2.item WHERE SI2.item ISNULL) ;
接下来我们把条件变一下,看看如何排除掉仙台店(仙台店的仓库中存在 “窗帘”,但商品表里没有 “窗帘”),让结果里只出现东京店。这类问题被称为 “精确关系除法”(exact relational division),即只选择没有剩余商品的店铺(与此相对,前一个问题被称为 “带余除法”(division with a remainder))。解决这个问题我们需要使用外连接。
1 2 3 4 5 6 7 8 9 10 11
-- 精确关系除法运算:使用外连接和COUNT函数 SELECT SI.shop FROM ShopItems AS SI LEFTOUTERJOIN Items AS I ON SI.item=I.item GROUPBY SI.shop HAVINGCOUNT(SI.item) = (SELECTCOUNT(item) FROM Items) -- 条件1 ANDCOUNT(I.item) = (SELECTCOUNT(item) FROM Items); -- 条件2
HAVING 子句中的条件还可以像下面这样写 。某个集合中,如果元素最大值和最小值相等,那么这个集合中肯定只有一种值。因为如果包含多种值,最大值和最小值肯定不会相等。极值函数可以使用参数字段的索引,所以这种写法性能更好 。
1 2 3 4 5 6
/* 用集合表达全称量化命题(2) */ SELECT team_id FROM Teams GROUPBY team_id HAVINGMAX(status) ='待命' ANDMIN(status) ='待命';
当然也可以把条件放在 SELECT 子句里,以列表形式显示出各个队伍是否所有队员都在待命,这样的结果更加一目了然。 需要注意的是,条件移到 SELECT 子句后,查询可能就不会被数据库优化了,所以性能上相比 HAVING 子句的写法会差一些。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
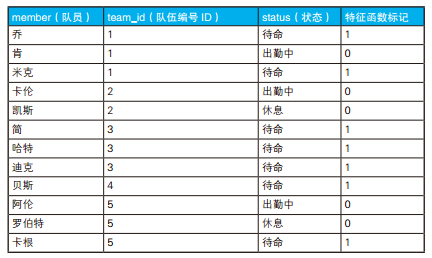
/* 列表显示各个队伍是否所有队员都在待命 */ SELECT team_id, CASEWHENMAX(status) ='待命'ANDMIN(status) ='待命' THEN'全都在待命' ELSE'队长!人手不够'ENDAS status FROM Teams GROUPBY team_id;
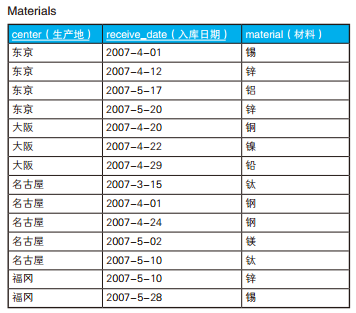
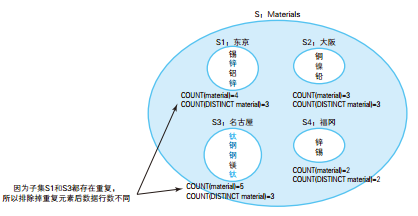
/* 选中材料存在重复的生产地 */ SELECT center FROM Materials GROUPBY center HAVINGCOUNT(material) <>COUNT(DISTINCT material);
center ------ 东京 名古屋
这个问题也可以通过将 HAVING 改写成 EXISTS 的方式来解决。用 EXISTS 改写后的 SQL 语句也能够查出重复的具体是哪一种材料,而且使用 EXISTS 后性能也很好。相反地,如果想要查出不存在重复材料的生产地有哪些,只需要把 EXISTS 改写为 NOT EXISTS 就可以了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* 存在重复的集合:使用EXISTS */ SELECT center, material FROM Materials M1 WHEREEXISTS (SELECT* FROM Materials M2 WHERE M1.center = M2.center AND M1.receive_date <> M2.receive_date AND M1.material = M2.material);
center material ------- --------- 东京 锌 东京 锌 名古屋 钛 名古屋 钢 名古屋 钢 名古屋 钛
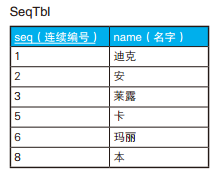
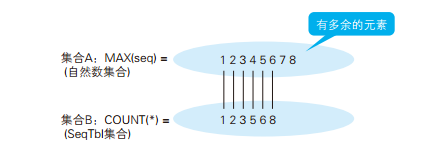
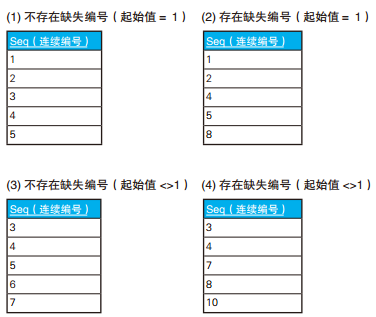
/* 如果有查询结果,说明存在缺失的编号:只调查数列的连续性 */ SELECT'存在缺失的编号'AS gap FROM SeqTbl HAVINGCOUNT(*) <>MAX(seq) -MIN(seq) +1;
/* 不论是否存在缺失的编号都返回一行结果 */ SELECTCASEWHENCOUNT(*) =0 THEN'表为空' WHENCOUNT(*) <>MAX(seq) -MIN(seq) +1 THEN'存在缺失的编号' ELSE'连续'ENDAS gap FROM SeqTbl;
查找最小的缺失编号。
1 2 3 4 5 6 7 8 9 10 11 12
/* 查找最小的缺失编号:表中没有1时返回1 */ -- Oracle: ORA-00937: not a single-group group function SELECTCASECOUNT(*) =0ORWHENMIN(seq) >1/* 最小值不是1时→返回1 */ THEN1 ELSE (SELECTMIN(seq +1) /* 最小值是1时→返回最小的缺失编号 */ FROM SeqTbl S1 WHERENOTEXISTS (SELECT* FROM SeqTbl S2 WHERE S2.seq = S1.seq +1)) ENDAS min_gap FROM SeqTbl;
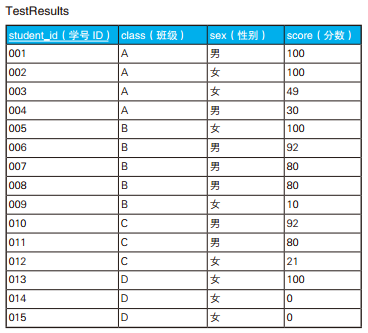
/* 75%以上的学生分数都在80分以上的班级 */ SELECT class FROM TestResults GROUPBY class HAVINGCOUNT(*) *0.75 <=SUM(CASEWHEN score >=80 THEN1 ELSE0END) ;
class ------- B
查询出分数在 50 分以上的男生的人数比分数在 50 分以上的女生的人数多的班级
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* 分数在50分以上的男生的人数比分数在50分以上的女生的人数多的班级 */ SELECT class FROM TestResults GROUPBY class HAVINGSUM(CASEWHEN score >=50AND sex ='男' THEN1 ELSE0END) >SUM(CASEWHEN score >=50AND sex ='女' THEN1 ELSE0END) ;
class ------- B C
查询出女生平均分比男生平均分高的班级
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* 比较男生和女生平均分的SQL语句(1):对空集使用AVG后返回0 */ SELECT class FROM TestResults GROUPBY class HAVINGAVG(CASEWHEN sex ='男' THEN score ELSE0END) <AVG(CASEWHEN sex ='女' THEN score ELSE0END) ;
class ------- A D
从表中的数据我们可以发现, D 班全是女生。在上面的解答中,用于判断男生的 CASE 表达式里分支 ELSE 0 生效了,于是男生的平均分就成了 0 分。对于女生的平均分约为 33.3 的 D 班,条件 0 <33.3 也成立,所以 D 班也出现在查询结果里了。这种处理方法看起来好像也没什么问题。但是,如果学号 013 的学生分数刚好也是 0 分,结果会怎么样呢?这种情况下,女生的平均分会变为 0 分,所以 D 班不会被查询出来。男生和女生的平均分都是 0,但是两个 0 的意义完全不同。女生的平均分是正常计算出来的,而男生的平均分本来就无法计算,只是强行赋值为 0 而已。真正合理的处理方法是,保证对空集求平均的结果是 “未定义”,就像除以 0 的结果是未定义一样。根据标准 SQL 的定义,对空集使用 AVG 函数时,结果会返回 NULL (用 NULL 来代替未定义这种做法本身也有问题,但是在这里我们不深究)。这回 D 班男生的平均分是 NULL。因此不管女生的平均分多少, D 班都会被排除在查询结果之外。这种处理方法和 AVG 函数的处理逻辑也是一致的。
1 2 3 4 5 6 7 8 9 10
/* 比较男生和女生平均分的SQL语句(2):对空集求平均值后返回NULL */ SELECT class FROM TestResults GROUPBY class HAVINGAVG(CASEWHEN sex ='男' THEN score ELSENULLEND) <AVG(CASEWHEN sex ='女' THEN score ELSENULLEND);
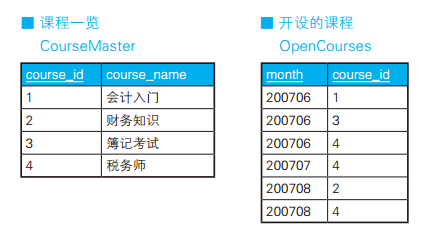
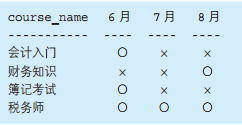
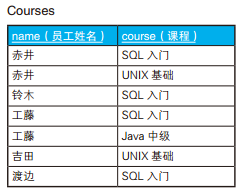
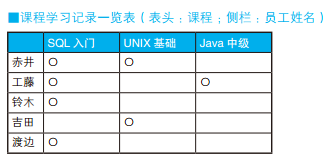
-- 水平展开求交叉表(1):使用外连接 SELECT C0.name, CASEWHEN C1.name ISNOTNULLTHEN'○'ELSENULLENDAS "SQL入门", CASEWHEN C2.name ISNOTNULLTHEN'○'ELSENULLENDAS "UNIX基础", CASEWHEN C3.name ISNOTNULLTHEN'○'ELSENULLENDAS "Java中级" FROM (SELECTDISTINCT name FROM Courses) C0 LEFTOUTERJOIN (SELECT name FROM Courses WHERE course ='SQL入门' ) C1 ON C0.name = C1.name LEFTOUTERJOIN (SELECT name FROM Courses WHERE course ='UNIX基础' ) C2 ON C0.name = C2.name LEFTOUTERJOIN (SELECT name FROM Courses WHERE course ='Java中级' ) C3 ON C0.name = C3.name;
-- 水平展开(2):使用标量子查询 SELECT C0.name, (SELECT'○' FROM Courses C1 WHERE course ='SQL入门' AND C1.name = C0.name) AS "SQL入门", (SELECT'○' FROM Courses C2 WHERE course ='UNIX基础' AND C2.name = C0.name) AS "UNIX基础", (SELECT'○' FROM Courses C3 WHERE course ='Java中级' AND C3.name = C0.name) AS "Java中级" FROM (SELECTDISTINCT name FROM Courses) C0;
使用 CASE 表达式。 CASE 表达式可以写在 SELECT 子句里的聚合函数内部,也可以写在聚合函数外部。这里,我们先把 SUM 函数的结果处理成 1 或者 NULL,然后在外层的 CASE 表达式里将 1 转换成 ○。 如果不使用聚合,那么返回结果的行数会是表 Courses 的行数,所以这里以参加培训课程的员工为单位进行聚合。这种做法和标量子查询的做法一样简洁,也能灵活地应对需求变更。
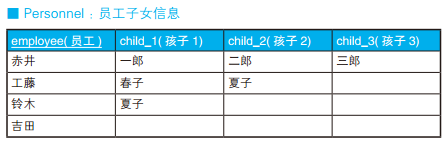
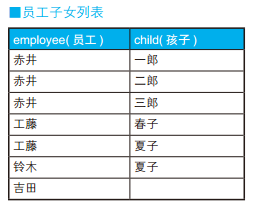
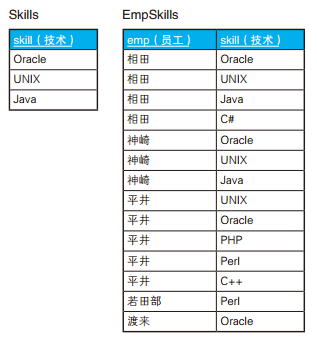
-- 获取员工子女列表的SQL语句(没有孩子的员工也输出) SELECT EMP.employee, CHILDREN.child FROM Personnel EMP LEFTOUTERJOIN (SELECT child_1 AS child FROM Personnel UNION SELECT child_2 AS child FROM Personnel UNION SELECT child_3 AS child FROM Personnel) CHILDREN ON CHILDREN.child IN (EMP.child_1, EMP.child_2, EMP.child_3);
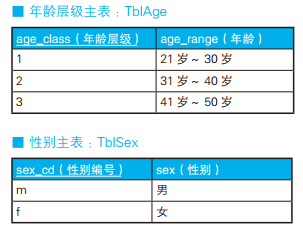
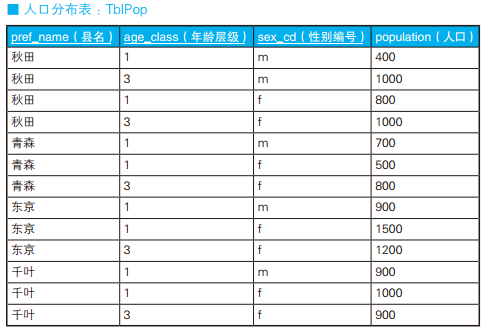
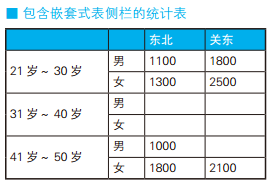
-- 使用外连接生成嵌套式表侧栏:错误的SQL语句 SELECT MASTER1.age_class AS age_class, MASTER2.sex_cd AS sex_cd, DATA.pop_tohoku AS pop_tohoku, DATA.pop_kanto AS pop_kanto FROM (SELECT age_class, sex_cd, SUM(CASEWHEN pref_name IN ('青森', '秋田') THEN population ELSENULLEND) AS pop_tohoku, SUM(CASEWHEN pref_name IN ('东京', '千叶') THEN population ELSENULLEND) AS pop_kanto FROM TblPop GROUPBY age_class, sex_cd) DATA RIGHTOUTERJOIN TblAge MASTER1 -- 外连接1:和年龄层级主表进行外连接 ON MASTER1.age_class = DATA.age_class RIGHTOUTERJOIN TblSex MASTER2 -- 外连接2:和性别主表进行外连接 ON MASTER2.sex_cd = DATA.sex_cd;
age_class sex_cd pop_tohoku pop_kanto --------- ------ ---------- --------- 1 m 11001800 1 f 13002500 3 m 1000 3 f 18002100
-- 停在第1个外连接处时:结果里包含年龄层级为2的数据 SELECT MASTER1.age_class AS age_class, DATA.sex_cd AS sex_cd, DATA.pop_tohoku AS pop_tohoku, DATA.pop_kanto AS pop_kanto FROM (SELECT age_class, sex_cd, SUM(CASEWHEN pref_name IN ('青森', '秋田') THEN population ELSENULLEND) AS pop_tohoku, SUM(CASEWHEN pref_name IN ('东京', '千叶') THEN population ELSENULLEND) AS pop_kanto FROM TblPop GROUPBY age_class, sex_cd) DATA RIGHTOUTERJOIN TblAge MASTER1 ON MASTER1.age_class = DATA.age_class; age_class sex_cd pop_tohoku pop_kanto --------- ------ ---------- --------- 1 m 11001800 1 f 13002500 2-- 存在年龄层级为 2 的数据 3 m 1000 3 f 18002100
-- 使用外连接生成嵌套式表侧栏:正确的SQL语句 SELECT MASTER.age_class AS age_class, MASTER.sex_cd AS sex_cd, DATA.pop_tohoku AS pop_tohoku, DATA.pop_kanto AS pop_kanto FROM (SELECT age_class, sex_cd, SUM(CASEWHEN pref_name IN ('青森', '秋田') THEN population ELSENULLEND) AS pop_tohoku, SUM(CASEWHEN pref_name IN ('东京', '千叶') THEN population ELSENULLEND) AS pop_kanto FROM TblPop GROUPBY age_class, sex_cd) DATA RIGHTOUTERJOIN (SELECT age_class, sex_cd FROM TblAge CROSSJOIN TblSex ) MASTER ON MASTER.age_class = DATA.age_class AND MASTER.sex_cd = DATA.sex_cd;
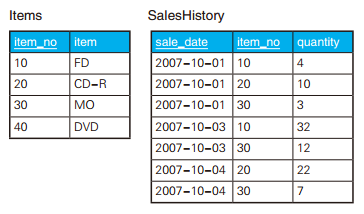
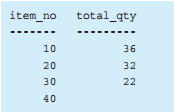
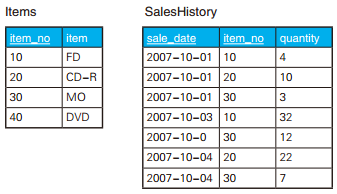
-- 解答(1):通过在连接前聚合来创建一对一的关系 SELECT I.item_no, SH.total_qty FROM Items I LEFTOUTERJOIN (SELECT item_no, SUM(quantity) AS total_qty FROM SalesHistory GROUPBY item_no) SH ON I.item_no = SH.item_no;
如果从性能角度考虑,上述 SQL 语句还是有些问题的。比如临时视图 SH 的数据需要临时存储在内存里,还有就是虽然通过聚合将 item_no 变成了主键,但是 SH 上却不存在主键索引,因此我们也就无法利用索引优化查询。要改善这个查询,关键在于导入 “把连接看作乘法运算” 这种视点。商品主表 Items 和视图 SH 确实是一对一的关系,但其实从 “item_no” 列看,表 Items 和表 SalesHistory 是一对多的关系。而且,当连接操作的双方是一对多关系时,结果的行数并不会增加。这就像普通乘法里任意数乘以 1 后,结果不会变化一样 。
1 2 3 4 5
-- 解答(2):先进行一对多的连接再聚合 SELECT I.item_no, SUM(SH.quantity) AS total_qty FROM Items I LEFTOUTERJOIN SalesHistory SH ON I.item_no = SH.item_no -- 一对多的连接 GROUPBY I.item_no;
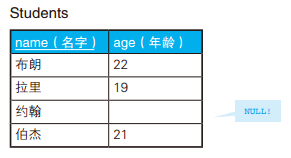
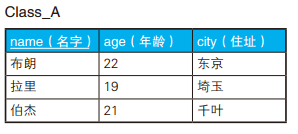
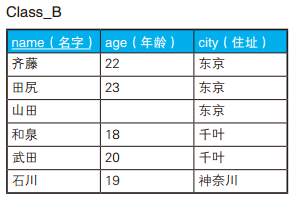
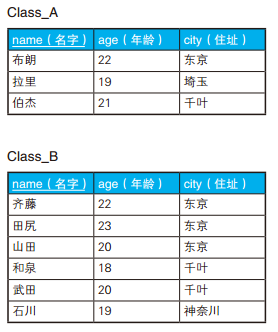
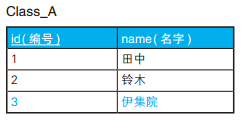
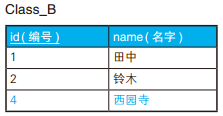
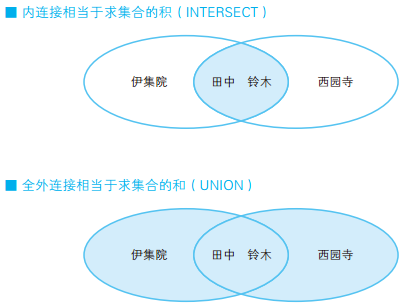
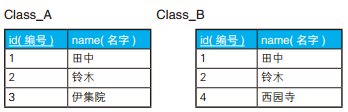
-- 全外连接保留全部信息 SELECTCOALESCE(A.id, B.id) AS id, --COALESCE 是 SQL 的标准函数,可以接受多个参数,功能是返回第一个非 NULL 的参数。 A.name AS A_name, B.name AS B_name FROM Class_A A FULLOUTERJOIN Class_B B ON A.id = B.id;
如果所用的数据库不支持全外连接,可以分别进行左外连接和右外连接,再把两个结果通过 UNION 合并起来,也能达到同样的目的 。这种写法虽然也能获取到同样的结果,但是代码比较冗长,而且使用两次连接后还要用 UNION 来合并,性能也不是很好。
1 2 3 4 5 6 7 8
-- 数据库不支持全外连接时的替代方案 SELECT A.id AS id, A.name, B.name FROM Class_A A LEFTOUTERJOIN Class_B B ON A.id = B.id UNION SELECT B.id AS id, A.name, B.name FROM Class_A A RIGHTOUTERJOIN Class_B B ON A.id = B.id;
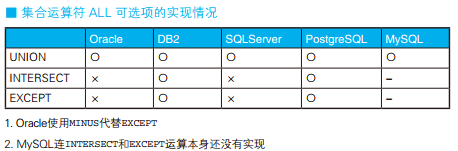
接下来我们考虑一下如何求两个集合的异或集。 SQL 没有定义求异或集的运算符,如果用集合运算符,可以有两种方法。一种是 (A UNION B) EXCEPT (A INTERSECT B) ,另一种是 (A EXCEPT B) UNION (B EXCEPT A) 。两种方法都比较麻烦,性能开销也会增大。
1 2 3 4 5 6 7 8 9 10 11
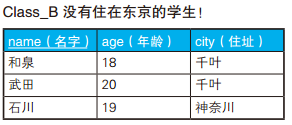
SELECTCOALESCE(A.id, B.id) AS id, COALESCE(A.name, B.name) AS name FROM Class_A A FULLOUTERJOIN Class_B B ON A.id = B.id WHERE A.name ISNULL OR B.name ISNULL;
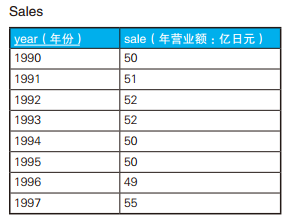
-- 求出是增长了还是减少了,抑或是维持现状(1):使用关联子查询 SELECT S1.year, S1.sale, CASEWHEN sale = (SELECT sale FROM Sales S2 WHERE S2.year = S1.year -1) THEN'→'-- 持平 WHEN sale > (SELECT sale FROM Sales S2 WHERE S2.year = S1.year -1) THEN'↑'-- 增长 WHEN sale < (SELECT sale FROM Sales S2 WHERE S2.year = S1.year -1) THEN'↓'-- 减少 ELSE'-'ENDAS var FROM Sales S1 ORDERBYyear;
year sale var ------ ---- --- 199050- 199151 ↑ 199252 ↑ 199352 → 199450 ↓ 199550 → 199649 ↓ 199755 ↑
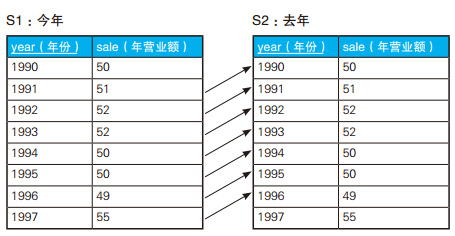
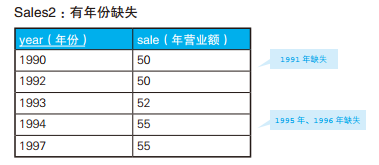
-- 查询与过去最临近的年份营业额相同的年份 SELECTyear, sale FROM Sales2 S1 WHERE sale = (SELECT sale FROM Sales2 S2 WHERE S2.year = (SELECTMAX(year) -- 条件2:在满足条件1的年份中,年份最早的一个 FROM Sales2 S3 WHERE S1.year > S3.year)) -- 条件1:与该年份相比是过去的年份 ORDERBYyear;
year sale ----- ---- 199250 199755
使用自连接。
1 2 3 4 5 6 7 8 9
-- 查询与过去最临近的年份营业额相同的年份:同时使用自连接 SELECT S1.year ASyear, S1.sale AS sale FROM Sales2 S1, Sales2 S2 WHERE S1.sale = S2.sale AND S2.year = (SELECTMAX(year) FROM Sales2 S3 WHERE S1.year > S3.year) ORDERBYyear;
通过这个方法,我们可以查询每一年与过去最临近的年份之间的营业额之差。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
-- 求每一年与过去最临近的年份之间的营业额之差(1):结果里不包含最早的年份 SELECT S2.year AS pre_year, S1.year AS now_year, S2.sale AS pre_sale, S1.sale AS now_sale, S1.sale - S2.sale AS diff FROM Sales2 S1, Sales2 S2 WHERE S2.year = (SELECTMAX(year) FROM Sales2 S3 WHERE S1.year > S3.year) ORDERBY now_year;
-- 求每一年与过去最临近的年份之间的营业额之差(2):使用自外连接。结果里包含最早的年份 SELECT S2.year AS pre_year, S1.year AS now_year, S2.sale AS pre_sale, S1.sale AS now_sale, S1.sale - S2.sale AS diff FROM Sales2 S1 LEFTOUTERJOIN Sales2 S2 ON S2.year = (SELECTMAX(year) FROM Sales2 S3 WHERE S1.year > S3.year) ORDERBY now_year;
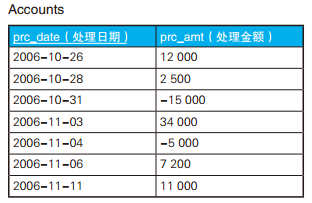
-- 求移动累计值(2):不满3行的时间区间也输出 SELECT prc_date, A1.prc_amt, (SELECTSUM(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date AND (SELECTCOUNT(*) FROM Accounts A3 WHERE A3.prc_date BETWEEN A2.prc_date AND A1.prc_date) <=3 ) AS mvg_sum FROM Accounts A1 ORDERBY prc_date;
-- 求移动累计值(3):不满3行的区间按无效处理 SELECT prc_date, A1.prc_amt, (SELECTSUM(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date AND (SELECTCOUNT(*) FROM Accounts A3 WHERE A3.prc_date BETWEEN A2.prc_date AND A1.prc_date ) <=3 HAVINGCOUNT(*) =3) AS mvg_sum -- 不满3行数据的不显示 FROM Accounts A1 ORDERBY prc_date;
-- 去掉聚合并输出 SELECT A1.prc_date AS A1_date, A2.prc_date AS A2_date, A2.prc_amt AS amt FROM Accounts A1, Accounts A2 WHERE A1.prc_date >= A2.prc_date AND (SELECTCOUNT(*) FROM Accounts A3 WHERE A3.prc_date BETWEEN A2.prc_date AND A1.prc_date ) <=3 ORDERBY A1_date, A2_date;
A1_date A2_date amt ---------- ---------- ------- 2006-10-262006-10-2612000
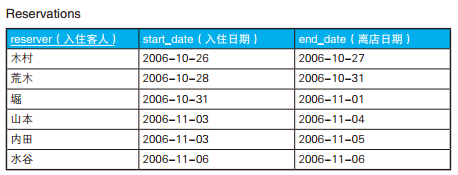
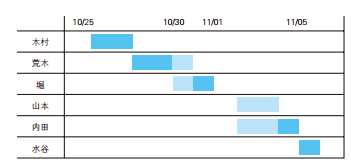
-- 求重叠的住宿期间 SELECT reserver, start_date, end_date FROM Reservations R1 WHEREEXISTS (SELECT* FROM Reservations R2 WHERE R1.reserver <> R2.reserver -- 与自己以外的客人进行比较 AND ( R1.start_date BETWEEN R2.start_date AND R2.end_date -- 条件(1):自己的入住日期在他人的住宿期间内 OR R1.end_date BETWEEN R2.start_date AND R2.end_date)); -- 条件(2):自己的离店日期在他人的住宿期间内
-- 升级版:把完全包含别人的住宿期间的情况也输出 SELECT reserver, start_date, end_date FROM Reservations R1 WHEREEXISTS (SELECT* FROM Reservations R2 WHERE R1.reserver <> R2.reserver AND ( ( R1.start_date BETWEEN R2.start_date AND R2.end_date OR R1.end_date BETWEEN R2.start_date AND R2.end_date) OR ( R2.start_date BETWEEN R1.start_date AND R1.end_date AND R2.end_date BETWEEN R1.start_date AND R1.end_date)));
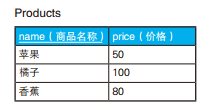
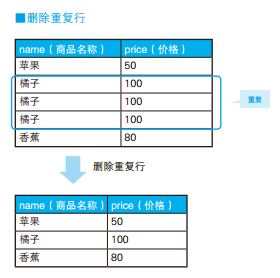
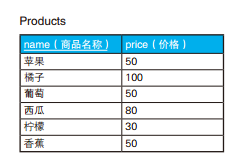
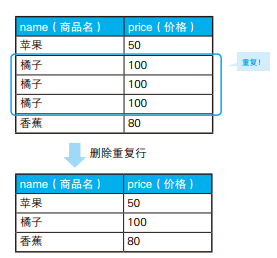
-- 删除重复行 :使用关联子查询 DELETEFROM Products WHERE rowid < ( SELECTMAX(P2.rowid) FROM Products P2 WHERE Products.name = P2. name AND Products.price = P2.price ) ;
1 2 3 4 5 6 7 8
-- 用于删除重复行的高效SQL语句(1):通过EXCEPT求补集 DELETEFROM Products WHERE rowid IN ( SELECT rowid FROM Products EXCEPT SELECTMAX(rowid) FROM Products GROUPBY name, price);
1 2 3 4 5
-- 删除重复行的高效SQL语句(2):通过NOT IN求补集 DELETEFROM Products WHERE rowid NOTIN ( SELECTMAX(rowid) FROM Products GROUPBY name, price);
-- 查询完成到了工程1的项目:面向集合的解法 SELECT project_id FROM Projects GROUPBY project_id HAVINGCOUNT(*) =SUM(CASEWHEN step_nbr <=1AND status ='完成'THEN1 WHEN step_nbr >1AND status ='等待'THEN1 ELSE0END);
project_id ----------- CS300
谓词逻辑的解法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
-- 查询完成到了工程1的项目:谓词逻辑的解法 SELECT* FROM Projects P1 WHERENOTEXISTS (SELECT status FROM Projects P2 WHERE P1.project_id = P2. project_id -- 以项目为单位进行条件判断 AND status <>CASEWHEN step_nbr <=1-- 使用双重否定来表达全称量化命题 THEN'完成' ELSE'等待'END);
-- 求所有缺失编号:EXCEPT版 SELECT seq FROM Sequence WHERE seq BETWEEN1AND12 EXCEPT SELECT seq FROM SeqTbl;
-- 求所有缺失编号:NOT IN版 SELECT seq FROM Sequence WHERE seq BETWEEN1AND12 AND seq NOTIN (SELECT seq FROM SeqTbl);
-- 动态地指定连续编号范围的SQL语句 SELECT seq FROM Sequence WHERE seq BETWEEN (SELECTMIN(seq) FROM SeqTbl) AND (SELECTMAX(seq) FROM SeqTbl) EXCEPT SELECT seq FROM SeqTbl;
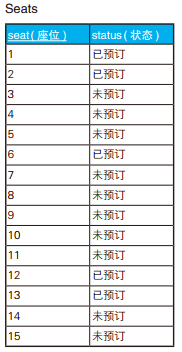
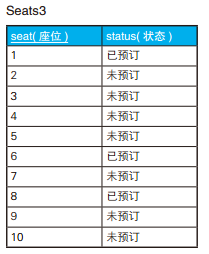
-- 找出需要的空位(1):不考虑座位的换排 SELECT S1.seat AS start_seat, '~' , S2.seat AS end_seat FROM Seats S1, Seats S2 WHERE S2.seat = S1.seat + (3-1) -- 决定起点和终点 ANDNOTEXISTS (SELECT* FROM Seats S3 WHERE S3.seat BETWEEN S1.seat AND S2.seat AND S3.status <>'未预订' ) ORDERBY start_seat;
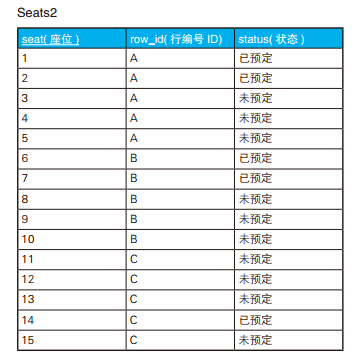
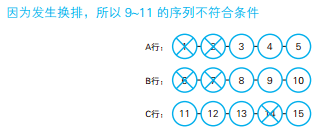
-- 找出需要的空位(2):考虑座位的换排 SELECT S1.seat AS start_seat, '~' , S2.seat AS end_seat FROM Seats2 S1, Seats2 S2 WHERE S2.seat = S1.seat + (3-1) --决定起点和终点 ANDNOTEXISTS (SELECT* FROM Seats2 S3 WHERE S3.seat BETWEEN S1.seat AND S2.seat AND ( S3.status <>'未预订' OR S3.row_id <> S1.row_id)) ORDERBY start_seat;
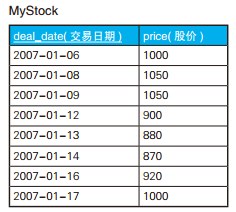
-- 求单调递增的区间的SQL语句:子集也输出 SELECT S1.deal_date AS start_date, S2.deal_date AS end_date FROM MyStock S1, MyStock S2 WHERE S1.deal_date < S2.deal_date -- 第一步:生成起点和终点的组合 ANDNOTEXISTS-- 第二步:描述区间内所有日期需要满足的条件 ( SELECT* FROM MyStock S3, MyStock S4 WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date AND S3.deal_date < S4.deal_date AND S3.price >= S4.price) ORDERBY start_date, end_date;
--排除掉子集,只取最长的时间区间 SELECTMIN(start_date) AS start_date, -- 最大限度地向前延伸起点 end_date FROM (SELECT S1.deal_date AS start_date, MAX(S2.deal_date) AS end_date -- 最大限度地向后延伸终点 FROM MyStock S1, MyStock S2 WHERE S1.deal_date < S2.deal_date ANDNOTEXISTS (SELECT* FROM MyStock S3, MyStock S4 WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date AND S3.deal_date < S4.deal_date AND S3.price >= S4.price) GROUPBY S1.deal_date) TMP GROUPBY end_date ORDERBY start_date;
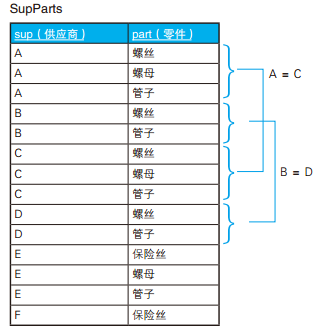
-- 慢 SELECT* FROM Class_A WHERE id IN (SELECT id FROM Class_B); -- 快 SELECT* FROM Class_A A WHEREEXISTS (SELECT* FROM Class_B B WHERE A.id = B.id);
使用 EXISTS 时更快的原因有以下两个。
如果连接列(id)上建立了索引,那么查询 Class_B 时不用查实际的表,只需查索引就可以了。
如果使用 EXISTS,那么只要查到一行数据满足条件就会终止查询,不用像使用 IN 时一样扫描全表。在这一点上 NOT EXISTS 也一样。
当 IN 的参数是子查询时,数据库首先会执行子查询,然后将结果存储在一张临时的工作表里(内联视图),然后扫描整个视图。很多情况下这种做法都非常耗费资源。使用 EXISTS 的话,数据库不会生成临时的工作表。 在 Oracle 数据库中,如果我们使用了建有索引的列,那么即使使用 IN 也会先扫描索引。此外,PostgreSQL 从版本 7.4 起也改善了使用子查询作为 IN 谓词参数时的查询速度。
参数是子查询时,使用连接代替 IN
要想改善 IN 的性能,除了使用 EXISTS,还可以使用连接。前面的查询语句就可以像下面这样 “扁平化”。
1 2 3 4
-- 使用连接代替 IN SELECT A.id, A.name FROM Class_A A INNERJOIN Class_B B ON A.id = B.id;
但是从性能上来看,第二条语句写法效率更高。原因通常有两个。第一个是在使用 GROUP BY 子句聚合时会进行排序,如果事先通过 WHERE 子句筛选出一部分行,就能够减轻排序的负担。第二个是在 WHERE 子句的条件里可以使用索引。 HAVING 子句是针对聚合后生成的视图进行筛选的,但是很多时候聚合后的视图都没有继承原表的索引结构。
在 GROUP BY 子句和 ORDER BY 子句中使用索引
一般来说, GROUP BY 子句和 ORDER BY 子句都会进行排序,来对行进行排列和替换。不过,通过指定带索引的列作为 GROUP BY 和 ORDER BY 的列,可以实现高速查询。特别是,在一些数据库中,如果操作对象的列上建立的是唯一索引,那么排序过程本身都会被省略掉。
-- 不会使用索引 SELECT* FROM SomeTable WHERE col_1 *1.1>100;
-- 会使用索引 SELECT* FROM SomeTable WHERE col_1 >100/1.1;
--在查询条件的左侧使用函数时,也不能用到索引。 SELECT* FROM SomeTable WHERE SUBSTR(col_1, 1, 1) ='a';
使用 IS NULL 谓词
通常,索引字段是不存在 NULL 的,所以指定 IS NULL 和 IS NOT NULL 的话会使得索引无法使用,进而导致查询性能低下。关于索引字段不存在 NULL 的原因,简单来说是 NULL 并不是值。非值不会被包含在值的集合中。
1 2 3
SELECT* FROM SomeTable WHERE col_1 ISNULL;
然而,如果需要使用类似 IS NOT NULL 的功能,又想用到索引,那么可以使用下面的方法,假设 “col_1” 列的最小值是 1。
1 2 3 4
--IS NOT NULL 的代替方案 SELECT* FROM SomeTable WHERE col_1 >0;
原理很简单,只要使用不等号并指定一个比最小值还小的数,就可以选出 col_1 中所有的值。因为 col_1 > NULL 的执行结果是 unknown,所以当 “col_1” 列的值为 NULL 的行不会被选择。不过,如果要选择 “非 NULL 的行”,正确的做法还是使用 IS NOT NULL。上面这种写法意思有些容易混淆,所以也不太推荐,请只在应急的情况下使用。
使用否定形式
下面这几种否定形式不能用到索引。
<>
!=
NOT IN
因此,下面的 SQL 语句也会进行全表扫描。
1 2 3
SELECT* FROM SomeTable WHERE col_1 <>100;
使用 OR
在 col_1 和 col_2 上分别建立了不同的索引,或者建立了(col_1,col_2)这样的联合索引时,如果使用 OR 连接条件,那么要么用不到索引,要么用到了但是效率比 AND 要差很多。如果无论如何都要使用 OR,那么有一种办法是位图索引。但是这种索引的话更新数据时的性能开销会增大,所以使用之前需要权衡一下利弊。
1 2 3 4
SELECT* FROM SomeTable WHERE col_1 >100 OR col_2 ='abc';
然而,对聚合结果指定筛选条件时不需要专门生成中间表,像下面这样使用 HAVING 子句就可以。HAVING 子句和聚合操作是同时执行的,所以比起生成中间表后再执行的 WHERE 子句,效率会更高一些,而且代码看起来也更简洁。
1 2 3 4
SELECT sale_date, MAX(quantity) FROM SalesHistory GROUPBY sale_date HAVINGMAX(quantity) >=10;
需要对多个字段使用 IN 谓词时,将它们汇总到一处
1 2 3 4 5 6 7 8
SELECT id, state, city FROM Addresses1 A1 WHERE state IN (SELECT state FROM Addresses2 A2 WHERE A1.id = A2.id) AND city IN (SELECT city FROM Addresses2 A2 WHERE A1.id = A2.id);
-- 通过在连接前聚合来创建一对一的关系 SELECT I.item_no, SH.total_qty FROM Items I LEFTOUTERJOIN (SELECT item_no, SUM(quantity) AS total_qty FROM SalesHistory GROUPBY item_no) SH ON I.item_no = SH.item_no;
-- 先进行一对多的连接再聚合 SELECT I.item_no, SUM(SH.quantity) AS total_qty FROM Items I LEFTOUTERJOIN SalesHistory SH ON I.item_no = SH.item_no -- 一对多的连接 GROUPBY I.item_no;