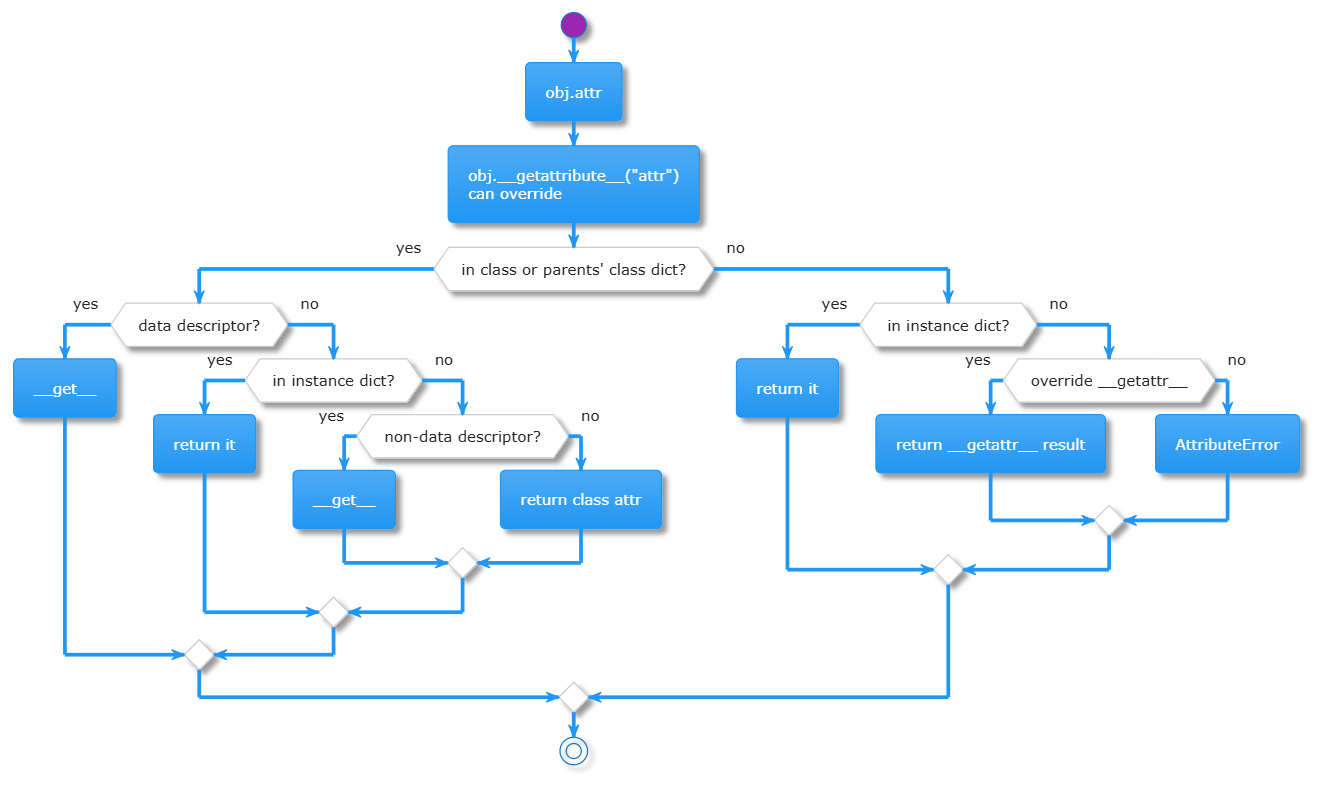
from: Python Deep Dive Course - Accompanying Materials
from: Indently
# IO# file openopen 返回的实际上是一个生成器对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import fileinputfor line in fileinput.input (): print(line) with fileinput.FileInput(files=("a.txt" , "b.txt" ), mode="r" ) as input : for idx, line in enumerate (input ): if input .isfirstline(): print(f"Reading file {input .filename()} ..." ) print(line) f = open (filename, 'r' ) print(hasattr (file, "__next__" ), hasattr (file, "__iter__" )) print(next (f)) print(next (f)) f.close()
# file lines1 2 3 4 5 6 7 8 9 10 11 k = 0 with open ('test.txt' ) as fid: for line in fid: k = k + 1 print(k) print(len ([line for line in open ('test.txt' ) ])) print(sum (1 for _ in open ('test.txt' )))
# file state
获取文件目录名,文件名
获取文件是否存在,是目录还是文件
获取文件大小
获取文件创建时间,上次访问时间,修改时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import os, sysimport timeimport datetimeprint(__file__, sys.argv[0 ]) path = r'E:\study_python\test\fast02.py' print(os.path.basename(path), os.path.dirname(path), os.path.split(path)) print(os.path.exists(path) ,os.path.isfile(path) ,os.path.isdir(path) ,os.path.getsize(path) ,os.path.getatime(path) ,datetime.datetime.fromtimestamp(os.path.getmtime(path)) ,os.path.getctime(path))
# os.walkremove node_modules
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import osimport shutilnode_modules_dirs = [] node_modules = 'node_modules' for root, dirs, files in os.walk(r'D:\study\node' ): for dir in dirs: if dir == node_modules: path = os.path.join(root, dir ) if node_modules not in path[0 :-len (node_modules)]: node_modules_dirs.append(path) print(path) print(len (node_modules_dirs), node_modules_dirs) for dir in node_modules_dirs: shutil.rmtree(dir ) print(f"Remove {dir } success!" )
上述方法缺点是遍历目录文件过多时,性能较差,比如实际找到项目目录的 node_modules 时不需要再向下遍历安装的模块中不符合条件的 node_modules, 这时可以使用如下方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osimport shutilnode_modules_dirs = [] def walk (dir for subpath in os.listdir(dir ): path = os.path.join(dir , subpath) if os.path.isdir(path): if path.endswith('node_modules' ): node_modules_dirs.append(path) else : walk(path) walk(r'D:\study\node' ) print(len (node_modules_dirs), node_modules_dirs) for dir in node_modules_dirs: shutil.rmtree(dir ) print(f"Remove {dir } success!" )
# StringIO1 2 3 4 5 6 7 8 9 10 from io import StringIOf = StringIO() f.write('hello, world' ) print(f.readline()) f.seek(0 ) print(f.readline())
# shutil.move and os.renameshutil means “shell utilities”.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 os.rename('path/to/file.txt' , 'path/to/new/directory/file.txt' ) shutil.move('path/to/file.txt' , 'path/to/new/directory/' ) shutil.move('path/to/file.txt' , 'path/to/new/directory/file.txt' ) os.rename('path/to/file.txt' , 'path/to/new/directory/file.txt' ) shutil.move('path/to/file.txt' , 'path/to/new/directory/' ) shutil.move('path/to/file.txt' , 'path/to/new/directory/file.txt' ) shutil.copy('path/to/file.txt' , 'path/to/new/directory/' ) shutil.copy('path/to/file.txt' , 'path/to/new/directory/file.txt' )
Keep the file modification time and so on.
1 2 3 4 5 6 7 8 9 from pathlib import Pathimport shutilfrom tkinter import filedialogsrc_path: str = filedialog.askopenfilename(title="Pick a file" ) directory: str = filedialog.askdirectory(title="Pick a location" ) dst_path: Path = Path(directory) / "copy.jpg" print(shutil.copy2(src=src_path, dst=dst_path))
# printPrints the values to a stream, or to sys.stdout by default.
1 2 3 4 5 6 7 def print ( *values: object , sep: str | None = " " , end: str | None = "\n" , file: SupportsWrite[str ] | None = None , flush: Literal[False ] = False None
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
file: a file-like object (stream); defaults to the current sys.stdout.
flush: whether to forcibly flush the stream.
print('*', end='\n') : 默认输出换行
print('*', end='') : 输出不换行
print('*', '*', sep=' ') : 默认以空格分隔多个值
print('*', '*', sep='@') : 用 @ 分隔多个值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 num_stars = int (input ('How many stars do you want ? ' )) for _ in range (num_stars): print('*' ,end='' ) print(*("*" for i in range (num_stars)), sep="-" , end="" ) print('*' , '*' , sep=' ' ) print('*' , '*' , sep='@' ) foods: list [str ] = ["Apples" , "Bananas" , "Oranges" ] print(*foods, sep=", " , end=".\n" )
# print %s, %r%r(repr) unambiguously recreate the object it represents 可以重建它所代表的对象。
1 2 3 4 5 6 7 8 9 10 11 s = "world" print("hello {!s}" .format (s), ',' , "hello %s" % s) print("hello {!r}" .format (s), ',' , "hello %r" % s) d = datetime.date.today() print("today is {!s}" .format (d), "today is %s" % d) print("today is {!r}" .format (d), "today is %r" % d)
__repr__() 方法返回一个实例的代码表示形式,通常用来重新构造这个实例。 内置的 repr () 函数返回这个字符串,跟我们使用交互式解释器显示的值是一样的。__str__() 方法将实例转换为一个字符串,使用 str () 或 print () 函数会输出这个字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Pair : def __init__ (self, x, y ): self.x = x self.y = y def __repr__ (self ): return 'Pair({0.x!r}, {0.y!r})' .format (self) def __str__ (self ): return '({0.x!s}, {0.y!s})' .format (self)
# fstring1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 n: int = 100000000 print(f'{n:_} ' ) print(f'{n:,} ' ) print(f"{n:.2 e} " ) var: str = 'var' print(f'{var:>20 } ' ) print(f'{var:<20 } ' ) print(f'{var:^20 } ' ) from datetime import datetimenow: datetime = datetime.now() print(f'{now:%d.%m.%y (%H:%M:%S)} ' ) print(f'{now:%c} ' ) print(f'{now:%I%p} ' ) now: datetime = datetime.now() print(f"{now:%Y-%m-%d} " ) date_spec: str = "%Y-%m-%d" print(f"{now:{date_spec} }" ) n: float = 1234.5678 print(f'{n:.2 f} ' ) print(f'{n:.0 f} ' ) print(f'{n:_.3 f} ' a: int = 5 b: int = 10 var: str = 'hello' print(f'{a + b = } ' ) print(f'{bool (a) = } ' ) print(f'{var = } ' ) custom_folder: str = "Babb" path: str = fr"\Desktop\STUDY\py-deep-dive\{custom_folder}" print(path) banana: str = "🍌" name: str = "Babb" today: date = datetime.now().date() print(f"{today!s} {name!s} says: {banana!s} " ) print(f"{today!r} {name!r} says: {banana!r} " ) print(f"{today!a} {name!a} says: {banana!a} " )
# logical lines1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 a = [ 1 , 2 , 3 , ] a = { "key1" : 1 , "key2" : 2 , "key3" : 3 , } def func ( a, b, c, pass func( 10 , 20 , 30 , ) a = True b = True c = True if a and b and c: pass a = """this\n \tis a string """ print(a)
# Container# string index1 2 3 4 5 6 7 s = 'hello' print(s[::-1 ]) s = 'PHP' print(s == s[::-1 ])
# string interning1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import sysimport timea = "hello" b = "hello" print(a is b) a = "the quick brown fox" b = "the quick brown fox" print(a is b) a = "the quick brown fox" * 1000 b = "the quick brown fox" * 1000 print(a is b) def compare_using_equals (n ): a = "the quick brown fox" * 1000 b = "the quick brown fox" * 1000 for i in range (n): if a == b: pass def compare_using_interning (n ): a = sys.intern("the quick brown fox" * 1000 ) b = sys.intern("the quick brown fox" * 1000 ) for i in range (n): if a is b: pass start = time.perf_counter() compare_using_equals(10000000 ) end = time.perf_counter() print("equality" , end - start) start = time.perf_counter() compare_using_interning(10000000 ) end = time.perf_counter() print("interning" , end - start)
# + and +=1 2 3 4 5 6 7 8 9 10 11 12 a = [1 , 2 ] c = a + [3 , 4 ] a += (5 , 6 ) a.extend(range (3 )) a = [1 , 2 , 3 ] print(id (a), a) b = range (4 , 8 , 2 ) a += b print(id (a), a)
# collections type checkcollections 模块定义了很多跟容器和迭代器(序列、映射、集合等)有关的抽象基类。
The Iterable abstract class was removed from collections in python 3.10,You can use Iterable from collections.abc instead.
numbers 库定义了跟数字对象(整数、浮点数、有理数等)有关的基类。
io 库定义了很多跟 I/O 操作相关的基类。可以用这些抽象基类检查数据类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import collectionsif isinstance (x, collections.Sequence): pass if isinstance (x, collections.Iterable): pass if isinstance (x, collections.Sized): pass if isinstance (x, collections.Mapping): pass
# iterable展开嵌套序列
1 2 3 4 5 6 7 8 9 10 11 12 13 from collections import Iterabledef flatten (items, ignore_types=(str , bytes ): for x in items: if isinstance (x, Iterable) and not isinstance (x, ignore_types): yield from flatten(x) else : yield x items = [1 , 2 , [3 , 4 , [5 , 6 ], 'abc' ], b'abc' ] for x in flatten(items): print(x)
# iteriter 函数可以接受一个可选的 callable 对象和一个标记(结尾)值作为输入参数。 当以这种方式使用的时候,它会创建一个迭代器, 这个迭代器会不断调用 callable 对象直到返回值和标记值相等为止。
1 2 3 4 5 6 7 f = open ('log2.txt' , 'r' ) for chunk in iter (lambda :f.read(10 ), '' ): print(chunk) f.close()
# generator1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 from contextlib import contextmanagerimport tracemallocdef process_line (line ): pass filepath = "large_data.csv" @contextmanager def trace_memory (): tracemalloc.start() yield current, peak = tracemalloc.get_traced_memory() print(f"Current memory usage : {current / 1024 **2 } MB" ) print(f"Peak memory usage : {peak / 1024 **2 } MB" ) tracemalloc.stop() with trace_memory(): with open (filepath, "r" ) as f: lines = f.readlines() for line in lines: process_line(line) class LineIterator : def __init__ (self, filepath ): self.file = open (filepath, "r" ) def __iter__ (self ): return self def __next__ (self ): line = self.file.readline() if line: return line else : self.file.close() raise StopIteration def line_generator (filepath ): with open (filepath, "r" ) as f: for line in f: yield line with trace_memory(): line_iter = LineIterator(filepath) for line in line_iter: process_line(line) with trace_memory(): line_gen = line_generator(filepath) for line in line_gen: process_line(line)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import mathclass FactIter : def __init__ (self, n ): self.n = n self.i = 0 def __iter__ (self ): return self def __next__ (self ): if self.i < self.n: result = math.factorial(self.i) self.i += 1 return result else : raise StopIteration fact_iter = FactIter(5 ) for i in fact_iter: print(i) def fact (): i = 0 def inner (): nonlocal i result = math.factorial(i) i += 1 return result return inner fact_iter = iter (fact(), math.factorial(5 )) for i in fact_iter: print(i) def factorials (n ): for i in range (n): yield math.factorial(i) fact_iter = factorials(5 ) print("__next__" in dir (fact_iter), "__iter__" in dir (fact_iter)) for i in fact_iter: print(i)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from collections import namedtupleCard = namedtuple("Card" , "rank suit" ) class CardDeck : SUITS = ("Spades" , "Hearts" , "Diamonds" , "Clubs" ) RANKS = tuple (range (2 , 11 )) + tuple ("JQKA" ) def __iter__ (self ): return CardDeck.card_gen() def __reversed__ (self ): return CardDeck.reversed_card_gen() @staticmethod def card_gen (): for suit in CardDeck.SUITS: for rank in CardDeck.RANKS: yield Card(rank, suit) @staticmethod def reversed_card_gen (): for suit in reversed (CardDeck.SUITS): for rank in reversed (CardDeck.RANKS): yield Card(rank, suit) print(list (CardDeck())[::13 ]) print(list (reversed (CardDeck()))[::13 ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def averager (): total = 0 count = 0 running_average = None while True : value = yield running_average total += value count += 1 running_average = total / count def running_averages (iterable ): average = averager() next (average) for value in iterable: running_average = average.send(value) print(running_average) running_averages([1 , 2 , 3 , 4 ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def parse_file (f_name ): print('opening file...' ) f = open (f_name, 'r' ) try : dialect = csv.Sniffer().sniff(f.read(2000 )) f.seek(0 ) next (f) reader = csv.reader(f, dialect=dialect) for row in reader: try : yield row except GeneratorExit: print('got a close...' ) return finally : print('cleaning up...' ) f.close() parser = parse_file('cars.csv' ) for row in itertools.islice(parser, 5 ): print(row) parser.close()
# generator state1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from inspect import getgeneratorstatedef gen (s ): for c in s: yield c g = gen("abc" ) print(getgeneratorstate(g)) print(next (g)) print(getgeneratorstate(g)) print(list (g)) print(getgeneratorstate(g)) def gen (s ): for c in s: print(getgeneratorstate(global_gen)) yield c global_gen = gen("abc" ) next (global_gen)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from inspect import getgeneratorstatedef echo (): while True : received = yield print(f"You said: {received} " ) e = echo() print(getgeneratorstate(e)) next (e)print(getgeneratorstate(e)) e.send("python" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import mathfrom inspect import getgeneratorstatedef coroutine (gen_fn ): def inner (*args, **kwargs ): gen = gen_fn(*args, **kwargs) next (gen) return gen return inner @coroutine def power_up (p ): result = None while True : received = yield result try : result = math.pow (received, p) except TypeError: result = None squares = power_up(2 ) cubes = power_up(3 ) print(squares.send(2 ), cubes.send(2 )) print(squares.send("a" )) squares.close() print(getgeneratorstate(squares)) squares.send(3 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from inspect import getgeneratorlocals, getgeneratorstatedef subgen (): yield 1 yield 2 def delegator (): a = 100 s = subgen() yield from s yield "subgen closed" d = delegator() print(getgeneratorstate(d), getgeneratorlocals(d)) next (d)print( getgeneratorstate(d), getgeneratorlocals(d) ) s = getgeneratorlocals(d)["s" ] print( s, getgeneratorstate(s) ) print( next (d), getgeneratorstate(d), getgeneratorstate(s) ) print( next (d), getgeneratorstate(d), getgeneratorstate(s) ) try : next (d) except StopIteration: pass print(getgeneratorstate(d), getgeneratorstate(s))
# yield from1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def is_iterable (item ): try : iter (item) except Exception: return False else : return True def flatten_gen (curr_item ): if is_iterable(curr_item): for item in curr_item: yield from flatten_gen(item) else : yield curr_item lst = [1 , 2 , [3 , 4 , [5 , 6 ]], [7 , [8 , 9 , 10 ]]] print(list (flatten_gen(lst))) lst = ["abc" , [1 , 2 , (3 , 4 )]] print(list (flatten_gen(lst)))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def is_iterable (item, *, str_is_iterable=True ): try : iter (item) except Exception: return False else : if isinstance (item, str ): if str_is_iterable and len (item) > 1 : return True else : return False else : return True def flatten_gen (curr_item, *, str_is_iterable=True ): if is_iterable(curr_item, str_is_iterable=str_is_iterable): for item in curr_item: yield from flatten_gen(item, str_is_iterable=str_is_iterable) else : yield curr_item lst = [1 , 2 , [3 , 4 , [5 , 6 ]], [7 , [8 , 9 , 10 ]]] print(list (flatten_gen(lst))) lst = ["abc" , [1 , 2 , (3 , 4 )]] print(list (flatten_gen(lst))) print(list (flatten_gen(lst, str_is_iterable=False )))
# defaultdict realize multidictdefaultdict 可以实现字典的值对应为列表或集合,列表会保持元素的插入顺序,集合会去除重复元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from collections import defaultdictd = defaultdict(list ) d['a' ].append(1 ) d['a' ].append(3 ) d['a' ].append(2 ) d['b' ].append(2 ) d['b' ].append(2 ) print(d) d = defaultdict(set ) d['a' ].add(1 ) d['a' ].add(3 ) d['a' ].add(2 ) d['b' ].add(2 ) d['b' ].add(2 ) print(d) d.setdefault('a' , []).append(1 ) d.setdefault('a' , []).append(2 ) d.setdefault('b' , set ()).add(2 ) d.setdefault('b' , set ()).add(2 ) print(d)
# zip and zip_longest1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 prices = { 'ACME' : 45.23 , 'AAPL' : 612.78 , 'IBM' : 205.55 , 'HPQ' : 37.20 , 'FB' : 10.75 } print(sorted (zip (prices.values(), prices.keys()))) prices_and_names = zip (prices.values(), prices.keys()) print(min (prices_and_names)) print(max (prices_and_names)) from itertools import zip_longestl1 = ['a' , 'b' , 'c' ] l2 = [10 , 20 , 30 , 40 ] print(list (zip_longest(l1, l2))) print(list (zip_longest(l1, l2, fillvalue="???" )))
1 2 3 4 5 6 7 8 9 10 11 l1 = [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] l2 = ["a" , "b" , "c" , "d" ] zip_result = [ (item1, item2) for index1, item1 in enumerate (l1) for index2, item2 in enumerate (l2) if index1 == index2 ] print(zip_result)
# dict1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 persons = { "john" : {"age" : 20 , "eye_color" : "blue" }, "jack" : {"age" : 25 , "eye_color" : "brown" }, "jill" : {"age" : 22 , "eye_color" : "blue" }, "eric" : {"age" : 35 }, "michael" : {"age" : 27 }, } eye_colors = {} for person, details in persons.items(): if "eye_color" in details: color = details["eye_color" ] else : color = "unknown" if color in eye_colors: eye_colors[color].append(person) else : eye_colors[color] = [person] print(eye_colors) eye_colors = {} for person, details in persons.items(): color = details.get("eye_color" , "unknown" ) person_list = eye_colors.get(color, []) person_list.append(person) eye_colors[color] = person_list print(eye_colors) eye_colors = defaultdict(list ) for person, details in persons.items(): color = details.get("eye_color" , "unknown" ) eye_colors[color].append(person) print(eye_colors)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from collections import defaultdictfrom functools import partialpersons = { "john" : defaultdict(lambda : "unknown" , age=20 , eye_color="blue" ), "jack" : defaultdict(lambda : "unknown" , age=20 , eye_color="brown" ), "jill" : defaultdict(lambda : "unknown" , age=22 , eye_color="blue" ), "eric" : defaultdict(lambda : "unknown" , age=35 ), "michael" : defaultdict(lambda : "unknown" , age=27 ), } eye_colors = defaultdict(list ) for person, details in persons.items(): eye_colors[details["eye_color" ]].append(person) print(eye_colors) eyedict = partial(defaultdict, lambda : "unknown" ) persons = { "john" : eyedict(age=20 , eye_color="blue" ), "jack" : eyedict(age=20 , eye_color="brown" ), "jill" : eyedict(age=22 , eye_color="blue" ), "eric" : eyedict(age=35 ), "michael" : eyedict(age=27 ), } eye_colors = defaultdict(list ) for person, details in persons.items(): eye_colors[details["eye_color" ]].append(person) print(eye_colors)
# dict_keys and dict_items字典的 keys () 和 items () 方法分别返回一个键视图对象和一个包含 (键,值) 对的元素视图对象, 支持集合并、交、差运算,values () 也是类似,但是不支持集合运算,因为值视图不能保证元素互不相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 a = { 'x' : 1 , 'y' : 2 , 'z' : 3 } b = { 'w' : 10 , 'x' : 11 , 'y' : 2 } print(a.keys(), a.items()) print(a.keys() & b.keys()) print(a.keys() - b.keys()) print(a.items() - b.items()) c = {key: a[key] for key in a.keys() - {'z' }} print(c)
# dict & set comprehension1 2 3 4 5 6 7 8 9 10 my_dict = {"Babb" : 18 , "Julian" : 28 } reversed_dict = {value: key for key, value in my_dict.items()} print(reversed_dict) my_set = {key for key, value in my_dict.items()} print(my_set) my_set = set (my_dict.keys()) print(my_set)
# dict update1 2 3 4 5 6 a: dict [str , int ] = {"a" : 1 , "b" : 2 } b: dict [str , int ] = {"a" : 2 , "c" : 3 } print(a | b) a |= b print(a)
# dict sort by valuesOrder is guaranteed since Python 3.7 in dictionaries.
1 2 3 scores: dict [str , int ] = {"Babb" : 101 , "Tom" : 42 , "Alice" : 34 , "Bob" : 68 } print(dict (sorted (scores.items(), key=lambda x: x[1 ]))) print(dict (sorted (scores.items(), key=lambda x: x[1 ], reverse=True )))
# UserDict1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from numbers import Realclass IntDict (dict def __setitem__ (self, key, value ): if not isinstance (value, Real): raise ValueError("Value must be a real number." ) super ().__setitem__(key, value) def __getitem__ (self, key ): return int (super ().__getitem__(key)) d = IntDict() d["a" ] = 10.5 print(d["a" ]) print(d.get("x" , "N/A" )) d["b" ] = 100.5 print(d.keys()) print(d.items()) d.update({"c" : 100.5 }) print(d) d.update({"d" : "python" }) print(d)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from collections import UserDictfrom numbers import Realclass IntDict (UserDict ): def __setitem__ (self, key, value ): if not isinstance (value, Real): raise ValueError("Value must be a real number." ) super ().__setitem__(key, value) def __getitem__ (self, key ): return int (super ().__getitem__(key)) d = IntDict() d["a" ] = 10.5 print(d["a" ]) print(d.get("x" , "N/A" )) d["b" ] = 100.5 print(d.keys()) print(d.items()) d.update({"c" : 100.5 }) print(d)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from collections import UserDictclass LimitedDict (UserDict ): def __init__ (self, keyset, min_value, max_value, *args, **kwargs ): self._keyset = keyset self._min_value = min_value self._max_value = max_value super ().__init__(*args, **kwargs) def __setitem__ (self, key, value ): if key not in self._keyset: raise KeyError("Invalid key name" ) if not isinstance (value, int ): raise ValueError("Value must be an integer type" ) if value < self._min_value or value > self._max_value: raise ValueError( f"Values must be between {self._min_value} and {self._max_value} " ) super ().__setitem__(key, value) d = LimitedDict({"red" , "green" , "blue" }, 0 , 255 , red=10 , green=10 , blue=10 ) print(d)
# ChainMap1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from collections import ChainMapd1 = {"a" : 1 , "b" : 2 } d2 = {"b" : 20 , "c" : 3 } d3 = {"c" : 30 , "d" : 4 } d = ChainMap(d1, d2, d3) print(d) print(d["b" ], d["c" ]) for k, v in d.items(): print(k, v) d1 = {"a" : 1 , "b" : 2 } d2 = {"c" : 3 , "d" : 4 } d = ChainMap(d1, d2) d3 = {"d" : 400 , "e" : 5 } d = d.new_child(d3) print(d) print(d.parents) d1 = {"a" : 1 , "b" : 2 } d2 = {"c" : 3 , "d" : 4 } d = ChainMap(d1, d2) print(d.maps, type (d.maps)) d3 = {"e" : 5 , "f" : 6 } d.maps.append(d3) print(d) d.maps.insert(0 , {"a" : 100 }) print(d) del d.maps[1 ]print(d)
# MappingProxyType1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from types import MappingProxyTypeclass Test : a = 100 print(repr (Test.__dict__)) print(type (Test.__dict__), type (Test().__dict__)) d = {"a" : 1 , "b" : 2 } mp = MappingProxyType(d) print( mp.keys(), mp.values(), mp.items(), mp.get("a" , "not found" ), mp.get("A" , "not found" ), ) d["a" ] = 100 d["c" ] = "new item" del d["b" ]print(d) print(mp, repr (mp))
# deque1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 from timeit import timeitfrom collections import OrderedDict, dequedef create_ordereddict (n=100 ): d = OrderedDict() for i in range (n): d[str (i)] = i return d def create_deque (n=100 ): return deque(range (n)) def pop_all_ordered_dict (n=1000 , last=True ): d = create_ordereddict(n) while True : try : d.popitem(last=last) except KeyError: break def pop_all_deque (n=1000 , last=True ): dq = create_deque(n) if last: pop = dq.pop else : pop = dq.popleft while True : try : pop() except IndexError: break n = 10_000 number = 1_000 results = dict () results["dict_create" ] = timeit( "create_ordereddict(n)" , globals =globals (), number=number ) results["deque_create" ] = timeit("create_deque(n)" , globals =globals (), number=number) results["dict_create_pop_last" ] = timeit( "pop_all_ordered_dict(n, last=True)" , globals =globals (), number=number ) results["dict_create_pop_first" ] = timeit( "pop_all_ordered_dict(n, last=False)" , globals =globals (), number=number ) results["deque_create_pop_last" ] = timeit( "pop_all_deque(n, last=True)" , globals =globals (), number=number ) results["deque_create_pop_first" ] = timeit( "pop_all_deque(n, last=False)" , globals =globals (), number=number ) results["dict_pop_last" ] = results["dict_create_pop_last" ] - results["dict_create" ] results["dict_pop_first" ] = results["dict_create_pop_first" ] - results["dict_create" ] results["deque_pop_last" ] = results["deque_create_pop_last" ] - results["deque_create" ] results["deque_pop_first" ] = results["deque_create_pop_first" ] - results["deque_create" ] for key, result in results.items(): print(f"{key} : {result} " )
# tuple1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 a = 1 , b = () c = (1 ,) d = (1 ) e = (1 +1 ) print(f"{type (a)=} " ) print(f"{type (b)=} " ) print(f"{type (c)=} " ) print(f"{type (d)=} " ) print(f"{type (e)=} " )
# tuple compare1 2 3 4 5 6 7 8 class A : def __init__ (self, name ): self.name = name print((1 , A('babb' )) < (2 , A('owen' ))) print((1 , A('babb' )) < (1 , A('owen' ))) print((1 , 1 , A('babb' )) < (1 , 2 , A('owen' ))) print((1 , ['1' , '2' ]) < (2 , ['1' , '3' ]))
# typing namedtuple1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from collections import namedtuplefrom typing import NamedTuplePoint = namedtuple("Point" , ["x" , "y" ]) p = Point(11 , y=22 ) print(p.x, p.y) print(p[0 ], p[1 ]) class Color (NamedTuple ): red: int green: int blue: int c = Color(red=55 , green=66 , blue=77 ) print(c.red, c.green, c.blue) print(c[0 ], c[1 ], c[2 ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import itertoolscounter = itertools.count(0 , 2 ) for i in counter: print(i) if i == 6 : break
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import itertoolsletters = ["A" , "B" , "C" ] cycler = itertools.cycle(letters) for i, letter in enumerate (cycler, start=1 ): print(f"{i} : {letter} " ) if i == 8 : break
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import itertoolsstring = "Hello" repeater = itertools.repeat(string, 5 ) for s in repeater: print(s)
1 2 3 4 5 6 7 8 9 10 11 import itertoolslst = [1 , 2 , 3 ] tee = itertools.tee(lst, 3 ) for it in tee: print(it, list (it))
1 2 3 4 5 6 7 8 9 10 import itertoolsimport operatornumbers = [1 , 2 , 3 , 4 , 5 ] accumulation = itertools.accumulate(numbers) print(list (accumulation)) accumulation = itertools.accumulate(numbers, operator.mul) print(list (accumulation))
1 2 3 4 5 6 7 import itertoolsa = [1 , 2 , 3 ] b = ["a" , "b" , "c" ] combined = itertools.chain(a, b, a, b) print(list (combined))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import itertoolsdef squares (): print("yielding 1st item" ) yield (i**2 for i in range (2 )) print("yielding 2nd item" ) yield (i**2 for i in range (2 , 4 )) print("yielding 3rd item" ) yield (i**2 for i in range (4 , 6 )) chained = itertools.chain(*squares()) for item in chained: print(item) chained = itertools.chain.from_iterable(squares()) for item in chained: print(item)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def squares (): print("yielding 1st item" ) yield (i**2 for i in range (2 )) print("yielding 2nd item" ) yield (i**2 for i in range (2 , 4 )) print("yielding 3rd item" ) yield (i**2 for i in range (4 , 6 )) def chain_iterables (*iterables ): for iterable in iterables: yield from iterable def chain_from_iterable (iterable ): for iterable in iterable: yield from iterable for item in chain_iterables(*squares()): print(item) for item in chain_from_iterable(squares()): print(item)
1 2 3 4 5 6 7 8 import itertoolslst = ["a" , "b" , "c" , "d" ] selectors = [0 , 1 , 1 ] compressed = itertools.compress(lst,selectors) print(list (compressed))
1 2 3 4 5 6 import itertoolslst = [1 , 2 , 3 , 4 , 5 , 1 , 2 ] remaining = itertools.dropwhile(lambda n: n < 3 , lst) print(list (remaining))
1 2 3 4 5 6 import itertoolslst = [1 , 2 , 3 , 4 , 5 , 1 , 2 ] taken = itertools.takewhile(lambda n: n < 3 , lst) print(list (taken))
1 2 3 4 5 6 7 8 9 10 11 12 13 import itertoolsfrom typing import Anylst = range (100 ) filtered = itertools.filterfalse(lambda n: n % 10 , lst) print(list (filtered)) lst: list [Any] = [0 , 1 , False , True ] filtered = itertools.filterfalse(None , lst) print(list (filtered))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import itertoolsfrom operator import itemgetterlst = [1 , 2 , 2 , 2 , 2 , 3 , 3 , 3 , 1 , 1 ] grouped = [list (g) for _, g in itertools.groupby(lst)] print(grouped) grouped = [list (g) for _, g in itertools.groupby(sorted (lst))] print(grouped) employees = [ [100 , '犬夜叉' , 2000 ], [200 , '杀生丸' , 3000 ], [100 , '桔梗' , 1000 ], [200 , '玲' , 800 ], [100 , '冥加' , 800 ], [300 , '奈落' , 4000 ] ] employees = sorted (employees, key=itemgetter(0 )) print(employees) for no, item in itertools.groupby(employees, itemgetter(0 )): print(list (item))
1 2 3 4 5 6 7 8 9 import itertoolslst = ["a" , "b" , "c" , "d" , "e" , "f" ] sliced = itertools.islice(lst, 2 ) print(list (sliced)) sliced = itertools.islice(lst, 2 , None ) print(list (sliced))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import itertoolsdef colors (): yield "red" yield "green" yield "blue" color_generater = colors() cycled = itertools.cycle(color_generater) sliced = itertools.islice(cycled, 10 ) print(list (sliced))
1 2 3 with open ("./test.csv" ) as f: for row in itertools.islice(f, 0 , 20 ): print(row, end="" )
1 2 3 4 5 6 7 8 9 10 import itertoolsimport operatorlst = [[1 , 2 ], [10 , 20 ], [100 , 200 ]] starmap_iterator = itertools.starmap(operator.mul, lst) print(list (starmap_iterator)) lst = [[1 , 2 , 3 ], [10 , 20 , 30 ], [100 , 200 , 300 ]] starmap_iterator = itertools.starmap(lambda x, y, z: x + y + z, lst) print(list (starmap_iterator))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import itertoolsimport operatorlst = [(2 , 3 ), (2 , 4 ), (2 , 5 )] star_mapped = itertools.starmap(operator.pow , lst) print(list (star_mapped)) lst = [(1 , 2 , 3 ), (2 , 4 ), (2 , 5 )] def example (*args ): temp = [] for arg in args: temp.append(f"{arg} X" ) return temp star_mapped = itertools.starmap(example, lst) print(list (star_mapped))
1 2 3 4 5 6 7 8 9 10 11 import itertoolsa = [1 , 2 , 3 , 4 , 5 ] b = ["a" , "b" , "c" ] c = [True , False ] zipped = itertools.zip_longest(a, b, c) print(list (zipped)) zipped = itertools.zip_longest(a, b, c, fillvalue="Unknown" ) print(list (zipped))
1 2 3 4 5 6 7 8 9 10 11 from itertools import batcheddata: list [int ] = [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] chunks: batched = batched(data, n=2 ) print(chunks) print(list (chunks)) chunks: batched = batched(data, n=3 ) print(next (chunks)) print(next (chunks)) print(next (chunks))
1 2 3 4 5 6 7 8 9 import itertoolss = "abcde" paired = itertools.pairwise(s) print(list (paired)) l = range (1 , 6 ) paired = itertools.pairwise(l) print(list (paired))
product 计算笛卡尔积。
100 以内所有勾股数,(3, 4, 5) 和 (4, 3, 5) 算不同的勾股数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from itertools import productfor i in range (1 , 100 ): for j in range (1 , 100 ): for k in range (1 , 100 ): if i * i + j * j == k * k: print(i, j, k) items = product('ABCD' , 'xy' ) print(items) for item in items: print(item) items = product(range (2 ), repeat=3 ) print(items) for item in items: print(item) for i, j, k in product(range (1 , 100 ), repeat=3 ): if i * i + j * j == k * k: print(i, j, k)
combinations_with_replacement 容器取 n 个元素,元素可以重复的组合。
100 以内所有勾股数,(3, 4, 5) 和 (4, 3, 5) 算相同的勾股数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from itertools import combinations_with_replacementfor i in range (1 , 100 ): for j in range (i, 100 ): for k in range (j, 100 ): if i * i + j * j == k * k: print(i, j, k) items = combinations_with_replacement('ABC' , 2 ) print(items) for item in items: print(item) for i, j, k in combinations_with_replacement(range (1 , 100 ), 3 ): if i * i + j * j == k * k: print(i, j, k)
combinations 容器取 n 个元素,元素不重复的组合。
有 10 个不同重量的砝码,任意取三个组合,总重量不在指定 [a, b] 重量区间的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from itertools import combinationsweight_list = [5 , 2 , 3 , 4 , 5 , 5 , 6 , 9 , 12 , 10 ] n = len (weight_list) a, b = 10 , 30 weight_range = set (range (a, b + 1 )) for i in range (n): for j in range (i + 1 , n): for k in range (j + 1 , n): total = weight_list[i] + weight_list[j] + weight_list[k] if total in weight_range: weight_range.remove(total) print(weight_range) items = combinations("ABC" , 2 ) print(items) for item in items: print(item) for i, j, k in combinations(weight_list, 3 ): total = i + j + k if total in weight_range: weight_range.remove(total) print(weight_range)
permutations 排列,每个顺序都称作一个排列。
SEND + MORE = MONEY, 每个字母代表不同的数字,S = ?, D = ? …
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from itertools import permutationsitems = permutations('ABC' , 2 ) print(items) for item in items: print(item) items = permutations(range (3 )) print(items) for item in items: print(item) for s, e, n, d, m, o, r, y in permutations(range (10 ), 8 ): if (s*1000 +e*100 +n*10 +d) + (m*1000 +o*100 +r*10 +e) == (m*10000 +o*1000 +n*100 +e*10 +y): if m != 0 and s != 0 : print(f"{s=} ,{e=} , {n=} , {d=} , {m=} , {o=} , {r=} , {y=} " )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from functools import reducefrom itertools import accumulateimport operatorlst = [1 , 2 , 3 , 4 ] result = reduce(operator.mul, lst) print(result) result = accumulate(lst, operator.mul) print(result) print(list (result)) result = accumulate(lst) print(list (result))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import operatordef running_reduce (fn, iterable, start=None ): it = iter (iterable) if start is None : acc = next (it) else : acc = start yield acc for item in it: acc = fn(acc, item) yield acc lst = [1 , 2 , 3 , 4 ] result = running_reduce(operator.mul, lst) print(list (result))
# exmaple1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import itertoolsdef grid (min_val, max_val, step, *, num_dimensions=2 ): axis = itertools.takewhile(lambda x: x <= max_val, itertools.count(min_val, step)) axes = itertools.tee(axis, num_dimensions) return itertools.product(*axes) print(list (grid(-1 , 1 , 0.5 ))) [
# slice1 2 3 4 5 6 7 8 9 iso_date_time = "2025-02-15T12:30:00.000Z" date_slice = slice (0 , 10 ) time_slice = slice (11 , 19 ) print(iso_date_time[date_slice], iso_date_time[time_slice]) print(iso_date_time[slice (10 )], iso_date_time[:10 ]) print(iso_date_time[slice (11 , None )], iso_date_time[11 :])
# hashable1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 k = [1 , 2 ] class MyList (list def __hash__ (self ): return id (self) def __eq__ (self, other ): return self is other k = MyList([1 , 2 ]) my_dict = {k: "value" } k.append(3 ) print(my_dict[k]) class MyClass : pass k = MyClass() my_dict = { k: "value" } print(my_dict[k])
# set membership is much faster than list or tuple membership1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import stringimport timeprint(string.ascii_letters) char_list = list (string.ascii_letters) char_tuple = tuple (string.ascii_letters) char_set = set (string.ascii_letters) def membership_test (n, container ): for _ in range (n): if "z" in container: pass start = time.perf_counter() membership_test(10000000 , char_list) end = time.perf_counter() print("list" , end - start) start = time.perf_counter() membership_test(10000000 , char_tuple) end = time.perf_counter() print("tuple" , end - start) start = time.perf_counter() membership_test(10000000 , char_set) end = time.perf_counter() print("set" , end - start)
# enumerate start1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 letters: str = "ABCD" for i, letter in enumerate (letters): print(f"{i} : {letter} " ) for i, letter in enumerate (letters, start=1 ): print(f"{i} : {letter} " )
# Counter1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from collections import Counterletters: list [str ] = ["A" , "A" , "A" , "B" , "C" , "C" , "D" ] counter: Counter = Counter(letters) print(counter) print(counter.total()) print(counter.most_common()) print(counter.most_common(n=2 )) c1 = Counter(a=1 , b=2 , c=3 ) c2 = Counter(b=1 , c=2 , d=3 ) c1.update(c2) print(c1) c1 = Counter(a=1 , b=2 , c=3 ) c2 = Counter(b=1 , c=2 , d=3 ) c1.subtract(c2) print(c1) c1 = Counter('aabbccddee' ) print(c1) c1.update('abcdef' ) print(c1) c1 = Counter('aabbcc' ) c2 = Counter('abc' ) print(c1, c2) print(c1 + c2) print(c1 - c2) print(c1 & c2) print(c1 | c2) c1 = Counter(a=10 , b=-10 ) print(+c1) print(-c1)
# TypedDict1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from typing import Required, TypedDict, NotRequiredclass Coordinate (TypedDict ): x: float y: float label: str category: NotRequired[str ] coordinate: Coordinate = {"x" : 10 , "y" : 10 , "label" : "Profit" , "category" : "Finance" } coordinate2: Coordinate = {"x" : 15 , "y" : 25 , "label" : "Expenses" } Vote = TypedDict("Vote" , {"for" : int , "against" : int }, total=True ) vote: Vote = {"for" : 100 , "against" : 200 } Vote = TypedDict("Vote" , {"for" : int , "against" : int }, total=False ) vote2: Vote = {"for" : 100 } Vote = TypedDict("Vote" , {"for" : int , "against" : Required[int ]}, total=False ) vote3: Vote = {"for" : 100 , "against" : 200 }
# itemgetter1 2 3 4 5 6 7 8 9 from operator import itemgetterelements: list [int ] = [1 , 2 , 3 , 4 , 5 ] first_and_last: itemgetter = itemgetter(0 , -1 , 2 ) print(first_and_last(elements)) items: dict [str , int ] = {"a" : 1 , "b" : 2 , "c" : 3 , "d" : 4 } a_and_c: itemgetter = itemgetter("a" , "c" ) print(a_and_c(items))
# remove list duplicates and keep order1 2 3 4 5 6 7 8 numbers: list [int ] = [1 , 1 , 3 , 3 , 3 , 2 , 2 , 1 , 2 , 3 , 4 , 4 ] print(list (set (numbers))) print(dict .fromkeys(numbers)) print(list (dict .fromkeys(numbers)))
# reversedreversed return an iterator, if the given sequence is too big, can consider using reversed.
1 2 3 4 5 6 7 8 9 10 11 12 name: str = "Babb" print(name[::-1 ], "" .join(reversed (name))) print(reversed (name)) reverse_iterator = reversed (name) print(next (reverse_iterator)) for item in reverse_iterator: print(item)
# flatten list1 2 3 4 5 6 7 8 9 10 from typing import Any, Callabletype Flatten = Callable[[list ], list ]flatten: Flatten = lambda target: sum ((flatten(sub) if isinstance (sub, list ) else [sub] for sub in target), start=[]) nested_list: list [Any] = [1 , [2 , [3 , 4 ]], ["a" , ["b" , ["c" , "d" ]]]] print(flatten(nested_list)) print([1 ] + [2 ] + []) print(sum ([[1 ], [2 ]], start=[]))
# secrets password generator1 2 3 4 5 6 7 8 9 10 11 import secretsimport stringfrom typing import Callablepassword_generator: Callable[[int ], str ] = lambda n: "" .join(secrets.choice(string.ascii_letters + string.digits + string.punctuation) for _ in range (n)) print(password_generator(5 )) print(password_generator(10 )) print(password_generator(20 ))
# sorted1 2 3 4 5 import randomlst = [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ] print(sorted (lst, key=lambda _: random.random()))
# random# random choices1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from collections import namedtupleimport randomlst = list (range (1000 )) choices_result = random.choices(lst, k=5 ) print(choices_result) lst = ["a" , "b" , "c" ] choices_result = random.choices(lst, k=5 , weights=[10 , 1 , 1 ]) print(choices_result) Freq = namedtuple("Freq" , "count freq" ) def freq_counts (lst ): total = len (lst) return {k: Freq(lst.count(k), 100 * lst.count(k) / total) for k in set (lst)} lst = ["a" , "b" , "c" ] result = freq_counts(random.choices(lst, k=1000 )) print(result) random.seed(0 ) result = freq_counts(random.choices(lst, k=1000 , weights=(8 , 1 , 1 ))) print(result) random.seed(0 ) result = freq_counts(random.choices(lst, k=1000 , cum_weights=(8 , 9 , 10 ))) print(result)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import randomfrom time import perf_counterdenominators = random.choices([0 , 1 ], k=1_000_000 ) start = perf_counter() for denominator in denominators: if denominator == 0 : continue else : 10 / denominator end = perf_counter() print( f"Avg elapsed time: {(end - start) / len (denominators)} " ) start = perf_counter() for denominator in denominators: try : 10 / denominator except ZeroDivisionError: continue end = perf_counter() print( f"Avg elapsed time: {(end - start) / len (denominators)} " ) denominators = random.choices([0 , 1 ], k=1_000_000 , weights=[1 , 9 ]) start = perf_counter() for denominator in denominators: if denominator == 0 : continue else : 10 / denominator end = perf_counter() print( f"Avg elapsed time: {(end - start) / len (denominators)} " ) start = perf_counter() for denominator in denominators: try : 10 / denominator except ZeroDivisionError: continue end = perf_counter() print( f"Avg elapsed time: {(end - start) / len (denominators)} " )
# random sample1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import randomfrom collections import Counterlst = range (20 ) random.seed(0 ) result = random.sample(lst, k=10 ) print(result) random.seed(0 ) result = random.choices(lst, k=10 ) print(result) import randomsuits = "C" , "D" , "H" , "A" ranks = tuple (range (2 , 11 )) + tuple ("JQKA" ) deck = [str (rank) + suit for suit in suits for rank in ranks] print(deck) result = Counter(random.sample(deck, k=20 )) print(result) result = Counter(random.choices(deck, k=20 )) print(result)
# Class# super()super 用来调用父类某个已经覆盖的方法,遵循菱形继承顺序,格式 super([type[, object-or-type]]) , 在 python3 中可以省略参数 super() , 在 python2 中使用 super(subtype, self) 。
mro() stands for Method Resolution Order
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class A : def spam (self ): print('A.spam' ) super ().spam() class B : def spam (self ): print('B.spam' ) class C (A, B ): pass c = C() c.spam() print(C.mro()) print(C.__mro__)
# __class__ point to class1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 In [12 ]: class A : ...: pass In [13 ]: a = A() In [14 ]: a.__class__ Out[14 ]: __main__.A In [15 ]: b = a.__class__() In [16 ]: b Out[16 ]: <__main__.A at 0x4fcb5f8 > In [17 ]: b.__class__ Out[17 ]: __main__.A
# calendar1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import calendarcal = calendar.month(2018 , 9 ) print(cal) ret = calendar.isleap(2018 ) print(ret)
# type() and isinstance1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class A : pass class B (A ): pass print(isinstance (A(), A)) print(type (A()) is A) print(isinstance (B(), A)) print(type (B()) is A) print(isinstance (1 , (float , int )))
# typing udt(user-defined types)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from typing import ListVector = List[float ] Matrix = List[Vector] def addMatrix (a : Matrix, b : Matrix ) -> Matrix: result = [] for i, row in enumerate (a): result_row =[] for j, _ in enumerate (row): result_row += [a[i][j] + b[i][j]] result += [result_row] return result x = [[1.0 , 0.0 ], [0.0 , 1.0 ]] y = [[2.0 , 1.0 ], [0.0 , -2.0 ]] z = addMatrix(x, y) print(z)
# dynamic monkey patch1 2 3 4 5 6 7 8 9 10 class Foo (): def bar (self ): print('Foo.bar' ) def bar (self ): print('Modified bar' ) Foo().bar() Foo.bar = bar Foo().bar()
# dynamic import动态导入是指模块可以以字符串的形式导入
1 2 3 4 5 6 7 8 9 module_names = ['sys' , 'os' , 're' ] modules = list (map (__import__ , module_names)) sys = modules[0 ] print(sys.version) import importlibmodule2 = importlib.import_module('sys' ) print(module2.version)
# import order1 2 3 4 5 6 7 8 9 10 11 import sysprint(sys.path) sys.path.append("/home/jbn/xxx" ) sys.path.insert(0 , "/home/jbn/xxx" ) print(sys.path)
# relative and absolute importAbsolute import is from the sys.path.
Relative import is from the __package__ , if one file as the start script, the __package__ is None.
# dataclass1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 from dataclasses import dataclass, fieldfrom datetime import datetimeimport randomfrom typing import ClassVar@dataclass(order=True ) class Person : name: str age: int height: int = field( default_factory=lambda : random.randint(150 , 200 ), repr =False ) count: ClassVar[int ] = 0 def __post_init__ (self ): Person.count += 1 p1 = Person(name="Alice" , age=30 ) p2 = Person(name="Alice" , age=30 ) print(p1 == p2) print(p1) print(p1.name) p3 = Person(name="Bob" , age=25 ) print(p1 < p3) print(p1.height) print(Person.count) @dataclass class AppConfig : debug: bool = False database_url: str = "sqlite:///:memory:" max_connections: int = 10 @dataclass class APIResponse : status_code: int data: dict headers: dict = field(default_factory=dict ) success: bool = field(init=False ) timestamp: datetime = field(default_factory=datetime.now) def __post_init__ (self ): self.success = 200 <= self.status_code < 300
frozen=True
1 2 3 4 5 6 7 8 9 10 11 from dataclasses import dataclass@dataclass(frozen=True ) class Fruit : name: str calories: float = 10 banana = Fruit("Banana" ) print(banana) banana.calories = 30
slots=True
1 2 3 4 5 6 7 8 9 10 11 from dataclasses import dataclass@dataclass(slots=True ) class Fruit : name: str calories: float apple = Fruit("Apple" , 20 ) print(apple) print(apple.__dict__)
kw_only=True
1 2 3 4 5 6 7 8 9 10 11 from dataclasses import dataclass@dataclass(kw_only=True ) class Fruit : name: str calories: float apple = Fruit(name="Apple" , calories=20 ) print(apple)
order=True
1 2 3 4 5 6 7 8 9 10 11 from dataclasses import dataclass@dataclass(order=True ) class Fruit : name: str calories: float apple = Fruit("Apple" , 20 ) orange = Fruit("Orange" , 20 ) print(apple < orange)
__post_init__
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from dataclasses import InitVar, dataclass, field@dataclass class Fruit : name: str grams: float cost_per_kg: float is_rare: InitVar[bool ] = False total_value: float = field(init=False ) def __post_init__ (self, is_rare: bool ) -> None : self.total_value = (self.grams / 1000 ) * self.cost_per_kg if is_rare: self.total_value *= 2 self.cost_per_kg *= 2 apple: Fruit = Fruit("Apple" , 2500 , 3 ) print(apple) orange: Fruit = Fruit("Orange" , 2000 , 3 , is_rare=True ) print(orange)
field default_factory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import randomimport stringfrom dataclasses import dataclass, field@dataclass(kw_only=True ) class Person : name: str address: str active: bool = True email_addresses: list [str ] = field(default_factory=list ) id : str = field(init=False , default_factory=lambda : "" .join(random.choices(string.ascii_uppercase, k=12 ))) search_string: str = field(init=False , repr =False ) def __post_init__ (self ) -> None : self.search_string = f"{self.name} {self.address} " person = Person(name="Babb" , address="Newyork" ) print(person) person = Person(name="Babb" , active=False , address="Newyork" , email_addresses=["babb@abc.com" , "babb@xyz.com" ]) print(person)
# property and descriptor1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 from math import piclass Circle : def __init__ (self, radius ): self.radius = radius @property def radius (self ): return self._radius @radius.setter def radius (self, value ): if not (isinstance (value, (int , float )) and value > 0 ): raise ValueError("Radius is required to be a positive number!" ) self._radius = value @radius.deleter def radius (self ): del self._radius @property def area (self ): return pi * self.radius * self.radius c = Circle(1 ) print(c.area) c.radius = 2 print(c.area) class PositiveNumber : def __set_name__ (self, owner, name ): self.private_name = f"_{name} " def __get__ (self, instance, owner ): return getattr (instance, self.private_name) def __set__ (self, instance, value ): if not (isinstance (value, (int , float )) and value > 0 ): raise ValueError(f"{self.private_name[1 :].capitalize()} must be positive." ) setattr (instance, self.private_name, value) class Rectangle : width = PositiveNumber() height = PositiveNumber() def __init__ (self, width, height ): self.width = width self.height = height r = Rectangle(2 , 2 ) print(r.width, r.height) r.height = -1 r.width = -1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class ValidString : def __init__ (self, min_length ): self.min_length = min_length def __set_name__ (self, owner_class, property_name ): self.property_name = property_name def __set__ (self, instance, value ): if not isinstance (value, str ): raise ValueError(f"{self.property_name} must be a string." ) if len (value) < self.min_length: raise ValueError( f"{self.property_name} must be at least {self.min_length} characters" ) instance.__dict__[self.property_name] = value def __get__ (self, instance, owner_class ): if instance is None : return self else : print(f"calling __get__ for {self.property_name} " ) return instance.__dict__.get(self.property_name, None ) class Person : first_name = ValidString(3 ) last_name = ValidString(3 ) p = Person() try : p.first_name = "Alex" p.last_name = "M" except ValueError as ex: print(ex) print(p.__dict__)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import numbersclass ValidType : def __init__ (self, type_ ): self._type = type_ def __set_name__ (self, owner_class, prop_name ): self.prop_name = prop_name def __set__ (self, instance, value ): if not isinstance (value, self._type): raise ValueError(f"{self.prop_name} must be of type {self._type.__name__} " ) instance.__dict__[self.prop_name] = value def __get__ (self, instance, owner_class ): if instance is None : return self else : return instance.__dict__.get(self.prop_name, None ) class Person : age = ValidType(int ) height = ValidType(float ) tags = ValidType(list ) favorite_foods = ValidType(tuple ) name = ValidType(str ) p = Person() try : p.age = 10.5 except ValueError as ex: print(ex) try : p.height = 10 except ValueError as ex: print(ex) print(isinstance (10.1 , numbers.Real), isinstance (10 , numbers.Real)) class Person : age = ValidType(int ) height = ValidType(numbers.Real) tags = ValidType(list ) favorite_foods = ValidType(tuple ) name = ValidType(str ) p = Person() p.height = 10 print(p.height)
property is descriptor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from numbers import Integralclass Person : def get_age (self ): return getattr (self, "_age" , None ) def set_age (self, value ): if not isinstance (value, Integral): raise ValueError("age: must be an integer." ) if value < 0 : raise ValueError("age: must be a non-negative integer." ) self._age = value age = property (fget=get_age, fset=set_age) p = Person() try : p.age = -10 except ValueError as ex: print(ex) prop = Person.age print(hasattr (prop, "__set__" ), hasattr (prop, "__get__" ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from numbers import Integralclass Person : @property def age (self ): return getattr (self, '_age' , None ) @age.setter def age (self, value ): if not isinstance (value, Integral): raise ValueError('age: must be an integer.' ) if value < 0 : raise ValueError('age: must be a non-negative integer.' ) self._age = value class Person : def get_age (self ): return getattr (self, '_age' , None ) age = property (get_age) def set_age (self, value ): if not isinstance (value, Integral): raise ValueError('age: must be an integer.' ) if value < 0 : raise ValueError('age: must be a non-negative integer.' ) self._age = value age = age.setter(set_age)
function and method is descriptor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import sysdef add (a, b ): return a + b print(hasattr (add, "__get__" ), hasattr (add, "__set__" )) owener = sys.modules["__main__" ] fn = add.__get__(None , owener) print(fn is add) class Person : def __init__ (self, name ): self.name = name def say_hello (self ): return f"{self.name} says hello" person = Person("Babb" ) bound_method = Person.say_hello.__get__(person, Person) print(bound_method) print(bound_method()) print(person.say_hello) print(Person.say_hello) print(person.say_hello.__func__ is Person.say_hello)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import typesclass MyFunc : def __init__ (self, func ): self._func = func def __get__ (self, instance, owner ): if instance is None : print("__get__ called from class" ) return self._func else : print("__get__ called from an instance" ) return types.MethodType(self._func, instance) def hello (self ): print(f"{self.name} says hello!" ) class Person : def __init__ (self, name ): self.name = name say_hello = MyFunc(hello) print(Person.say_hello) p = Person("Babb" ) print(p.say_hello) print(p.say_hello.__func__)
# enum1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 from enum import Enum, IntEnum, StrEnum, autoclass Color (Enum ): RED = 1 GREEN = 2 BLUE = 3 @classmethod def print_members (cls ): for color in cls: print(f"{color.name} = {color.value} " ) Color.print_members() print(type (Color.RED)) print(Color.RED.name) print(Color.RED.value) print(Color.RED == Color(1 )) print(Color.RED == 1 ) class IntColor (IntEnum ): RED = 1 GREEN = 2 BLUE = 3 @classmethod def print_members (cls ): for color in cls: print(f"{color.name} = {color.value} " ) IntColor.print_members() print(IntColor.RED == 1 ) class StrColor (StrEnum ): RED = "red" GREEN = "green" BLUE = "blue" @classmethod def print_members (cls ): for color in cls: print(f"{color.name} = {color.value} " ) StrColor.print_members() print(StrColor.RED == "red" ) class AutoColor (StrEnum ): RED = auto() GREEN = auto() BLUE = auto() @classmethod def print_members (cls ): for color in cls: print(f"{color.name} = {color.value} " ) AutoColor.print_members() class HTTPStatus (IntEnum ): OK = 200 NOT_FOUND = 404 INTERNAL_SERVER_ERROR = 500 def handle_http_status (status: HTTPStatus ): if status == HTTPStatus.OK: return "Success" elif status == HTTPStatus.NOT_FOUND: return "Not Found" elif status == HTTPStatus.INTERNAL_SERVER_ERROR: return "Server Error" else : return "Unknown Status" class Light : def __init__ (self, color: Color ): self.color = color light = Light(Color.RED) print(light.color)
enum aliases
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from enum import Enumclass Color (Enum ): red = 1 crimson = 1 carmine = 1 blue = 2 aquamarine = 2 print(list (Color)) print(Color.crimson, Color.carmine, Color.aquamarine) print(Color.carmine is Color.red) print(Color(1 ), Color["crimson" ]) print(Color.crimson in Color, 1 in Color) print(Color.__members__) import enum@enum.unique class Color (Enum ): red = 1 crimson = 1 carmine = 1 blue = 2 aquamarine = 2
Extending Custom Enumerations
We can also extend (subclass) our custom enumerations - but only under certain circumstances: as long as the enumeration we are extending does not define any members :
1 2 3 4 5 6 7 8 9 10 class Color (Enum ): RED = 1 GREEN = 2 BLUE = 3 try : class ColorAlpha (Color ): ALPHA = 4 except TypeError as ex: print(ex)
But this would work:
1 2 3 4 5 6 7 8 9 10 class ColorBase (Enum ): def hello (self ): return f'{str (self)} says hello!' class Color (ColorBase ): RED = 'red' GREEN = 'green' BLUE = 'blue' print(Color.RED.hello())
Custom OrderedEnum
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from enum import Enumfrom functools import total_ordering@total_ordering class OrderedEnum (Enum ): """Creates an ordering based on the member values. So member values have to support rich comparisons. """ def __lt__ (self, other ): if isinstance (other, OrderedEnum): return self.value < other.value return NotImplemented class Number (OrderedEnum ): ONE = 1 TWO = 2 THREE = 3 class Dimension (OrderedEnum ): D1 = 1 , D2 = 1 , 1 D3 = 1 , 1 , 1 print(Number.ONE < Number.THREE, Number.ONE >= Number.ONE) print(Dimension.D1 < Dimension.D3, Dimension.D1 >= Dimension.D2)
Custom TwoValueEnum
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class TwoValueEnum (Enum ): def __new__ (cls, member_value, member_phrase ): member = object .__new__(cls) member._value_ = member_value member.phrase = member_phrase return member class AppStatus (TwoValueEnum ): OK = (0 , 'No Problem!' ) FAILED = (1 , 'Crap!' ) print(AppStatus.FAILED, AppStatus.FAILED.name, AppStatus.FAILED.value, AppStatus.FAILED.phrase)
# abstract class1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from abc import ABC, abstractmethodclass Course (ABC ): @abstractmethod def enroll (self, student ): print(f"{student} enrolled in the Course." ) class MathCourse (Course ): def enroll (self, student ): print(f"{student} enrolled in the Math Course." ) class HistoryCourse (Course ): def enroll (self, student ): print(f"{student} enrolled in the History Course." ) courses = [MathCourse(), HistoryCourse()] for course in courses: course.enroll("Alice" ) course.enroll("Bob" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from abc import ABC, abstractmethodclass Animal (ABC ): def __init__ (self, name: str ) -> None : self.name = name @abstractmethod def sound (self ) -> None : ... @abstractmethod def move (self ) -> None : ... class Cat (Animal ): def __init__ (self, name: str ) -> None : super ().__init__(name) def sound (self ) -> None : print("Meow!" ) def move (self ) -> None : print("Paw paw paw..." ) cat: Cat = Cat("Tom" ) cat.sound() cat.move()
# bultin type constructor without parameter1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 print(int ()) print(bool ()) print(repr (str ())) print(list ()) print(set ()) print(dict ()) print(tuple ()) from collections import defaultdictd: defaultdict[str , int ] = defaultdict(int ) print(d["a" ])
# keyword and soft keyword1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import keywordprint(keyword.softkwlist) print(keyword.kwlist) self = "self" this = self print(this) match = "match" switch = match print(switch) as = 10 print(as )
# class arribute and instance arribute1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Car : fuel_type: str = "electric" def __init__ (self, brand: str ) -> None : self.brand = brand bmw: Car = Car("BMW" ) print(bmw.__dict__) print(bmw.fuel_type) bmw.fuel_type = "disel" print(Car.fuel_type) print(bmw.__dict__)
# __slots__
UsingSlots
Why Use __slots__ ? The short answer is slots are more efficient in terms of memory space and speed of access, and a bit safer than the default Python method of data access. By default, when Python creates a new instance of a class, it creates a __dict__ attribute for the class. The __dict__ attribute is a dictionary whose keys are the variable names and whose values are the variable values. This allows for dynamic variable creation but can also lead to uncaught errors. For example, with the default __dict__ , a misspelled variable name results in the creation of a new variable, but with __slots__ it raises in an AttributeError .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Location : __slots__ = 'name' , '_longitude' , '_latitude' def __init__ (self, name, longitude, latitude ): self._longitude = longitude self._latitude = latitude self.name = name @property def longitude (self ): return self._longitude @property def latitude (self ): return self._latitude print(Location.__dict__) Location.map_service = "Google Maps" print(Location.__dict__) l = Location('Mumbai' , 19.0760 , 72.8777 ) print(l.name, l.longitude, l.latitude) try : l.__dict__ except AttributeError as ex: print(ex) try : l.map_link = 'http://maps.google.com/...' except AttributeError as ex: print(ex)
dataclass use slots
1 2 3 4 5 6 7 8 9 10 11 from dataclasses import dataclass@dataclass(slots=True ) class Fruit : name: str calories: float apple = Fruit("Apple" , 20 ) print(apple) print(apple.__dict__)
# private attribute1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from uuid import uuid4class User : def __init__ (self ) -> None : self._id = uuid4() def _get_id (self ): return self._id user = User() print(user._get_id(), user._id) class User : def __init__ (self ) -> None : self.__id = uuid4() def __get_id (self ): return self.__id user = User() print(user.__dict__) print(user._User__id, user._User__get_id())
# typing1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 from __future__ import annotations from datetime import datetimefrom typing import Callable, Literal, TypeVar, Sequence, Optionalfrom collections.abc import Iterableclass Student : def __init__ ( self, name: str , birthdate: datetime | str , sex: Literal["M" , "F" ], courses: list [str ], scores: dict [str , float ], location: tuple [float , float ] | None , ): self.name = name self.birthdate = birthdate self.sex = sex self.courses = courses self.scores = scores self.location = location def follow (self, other: Student ): pass s = Student( name="Alice" , birthdate="2000-01-01" , sex="F" , courses=["Math" , "Science" ], scores={"Math" : 95.5 }, location=(40.7128 , -74.0060 ), ) def print_names (names: Iterable[str ] ) -> None : for name in names: print(name) print_names(["Alice" , "Bob" , "Charlie" ]) print_names(("Alice" , "Bob" , "Charlie" )) def add (x: int , y: int ) -> int: return x + y callable : Callable[[int , int ], int ] = addprint(callable (2 , 3 )) def apply_function (func: Callable[[int , int ], int ], x: int , y: int ) -> int: return func(x, y) print(apply_function(add, 5 , 7 )) def add_two_items[T: (int, str)](a: T, b: T) -> T: return a + b U = TypeVar("U" , int , str ) def add_two_items_again (a: U, b: U ) -> U: return a + b print(add_two_items(1 , 2 )) print(add_two_items("Hello, " , "World!" )) Num = float | int def add_num (a: Num, b: Num ) -> Optional[Num]: if a <= 0 or b <= 0 : return None return a + b print(add_num(1 , 2 )) print(add_num(1.1 , 2.2 )) def print_num (n: Num ) -> None : print(n) result = add_num(-1 , 1 ) if result: print_num(result) def print_num_list (lst: Sequence[Num] ) -> None : for n in lst: print(n) int_list: list [int ] = [1 , 2 , 3 ] print_num_list(int_list) from typing import TypeAlias, Literaltype Mode = Literal["r" , "w" , "a" ]def open_file (file: str , mode: Mode ) -> str: return f"Reading {file} in '{mode} ' mode" print(open_file("test.txt" , "r" )) print(open_file("test.txt" , "o" ))
Never and NoReturn
Never and NoReturn have the same meaning in the type system and static type checkers treat both equivalently.
Added in version 3.6.2: Added NoReturn .
Added in version 3.11: Added Never .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from enum import Enumfrom typing import Never, NoReturndef assert_never (arg: Never ) -> NoReturn: raise ValueError("Expected code is unreachable" ) class State (Enum ): OFF = 0 ON = 1 LIMBO = 2 state: State = State.ON if state == State.ON: print("Turned on" ) elif state == State.OFF: print("Turned off" ) else : assert_never(state)
# Dunder methods# __get_item__1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from dataclasses import dataclass@dataclass(kw_only=True ) class Fruit : name: str grames: float class Basket : def __init__ (self, *, fruits: list [Fruit] ) -> None : self.fruits = fruits def __getitem__ (self, fruit_name: str ) -> list[Fruit]: return [fruit for fruit in self.fruits if fruit.name.lower() == fruit_name.lower() ] fruits: list [Fruit] = [Fruit(name="Apple" , grames=2500 ), Fruit(name="Apple" , grames=1500 ), Fruit(name="Orange" , grames=2500 ), Fruit(name="Apple" , grames=2500 ), Fruit(name="Banana" , grames=500 ),] basket: Basket = Basket(fruits=fruits) apples = basket["apple" ] print(apples)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from functools import lru_cacheclass Fib : def __init__ (self, n ): self.n = n def __len__ (self ): return self.n def __getitem__ (self, s ): if isinstance (s, int ): if s < 0 : s += self.n if s < 0 or s >= self.n: raise IndexError else : return Fib._fib(s) else : rng = range (*s.indices(self.n)) return [Fib._fib(i) for i in rng] @staticmethod @lru_cache(2 **10 def _fib (n ): if n < 2 : return 1 else : return Fib._fib(n - 1 ) + Fib._fib(n - 2 ) fib = Fib(10 ) print(list (fib)) print(fib[0 ], fib[5 ]) print(fib[::-1 ]) print(fib[1 ::2 ])
# __set_item__1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 from collections import namedtuplePoint = namedtuple("Point" , "x y" ) class Polygon : def __init__ (self, *pts ): if pts: self._pts = [Point(*pt) for pt in pts] else : self._pts = [] def __repr__ (self ): pts_str = ", " .join([str (pt) for pt in self._pts]) return f"Polygon({pts_str} )" def __len__ (self ): return len (self._pts) def __getitem__ (self, s ): return self._pts[s] def __setitem__ (self, s, value ): try : rhs = [Point(*pt) for pt in value] is_single = False except TypeError: try : rhs = Point(*value) is_single = True except TypeError: raise TypeError("Invalid Point or iterable of Points" ) if (isinstance (s, int ) and is_single) or isinstance (s, slice ) and not is_single: self._pts[s] = rhs else : raise TypeError("Incompatible index/slice assignment" ) def __add__ (self, pt ): if isinstance (pt, Polygon): new_pts = self._pts + pt._pts return Polygon(*new_pts) else : raise TypeError("can only concatenate with another Polygon" ) def append (self, pt ): self._pts.append(Point(*pt)) def extend (self, pts ): if isinstance (pts, Polygon): self._pts = self._pts + pts._pts else : points = [Point(*pt) for pt in pts] self._pts = self._pts + points def __iadd__ (self, pts ): self.extend(pts) return self def insert (self, i, pt ): self._pts.insert(i, Point(*pt)) def __delitem__ (self, s ): del self._pts[s] def pop (self, i ): return self._pts.pop(i) p = Polygon((0 , 0 ), (1 , 1 ), (2 , 2 )) print(p) print(p[0 ]) p[0 ] = (1 , 1 ) print(p) p[0 :2 ] = [(0 , 0 ), (0 , 1 )] print(p)
# __iter__1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class Cities : def __init__ (self ): self._cities = ["Paris" , "Berlin" , "Rome" , "Madrid" , "London" ] self._index = 0 def __len__ (self ): return len (self._cities) def __iter__ (self ): print("Cities __iter__ called" ) return self.CityIterator(self) def __getitem__ (self, s ): print(f"Cities __getitem__ {s} " ) return self._cities[s] class CityIterator : def __init__ (self, city_obj ): print("CityIterator new object" ) self._city_obj = city_obj self._index = 0 def __iter__ (self ): print("CityIterator __iter__ called" ) return self def __next__ (self ): print("CityIterator __next__ called" ) if self._index < len (self._city_obj): item = self._city_obj._cities[self._index] self._index += 1 return item else : raise StopIteration cities = Cities() print(cities[0 ]) print(cities[0 :4 :2 ]) for city in cities: print(city)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Cities : def __init__ (self ): self._cities = ["Paris" , "Berlin" , "Rome" , "Madrid" , "London" ] self._index = 0 def __len__ (self ): return len (self._cities) def __getitem__ (self, s ): print(f"Cities __getitem__ {s} " ) return self._cities[s] cities = Cities() for city in cities: print(city)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 from collections import namedtuple_SUITS = ("Spades" , "Hearts" , "Diamonds" , "Clubs" ) _RANKS = tuple (range (2 , 11 )) + tuple ("JQKA" ) Card = namedtuple("Card" , "rank suit" ) class CardDeck : def __init__ (self ): self.length = len (_SUITS) * len (_RANKS) def __len__ (self ): return self.length def __iter__ (self ): return self.CardDeckIterator(self.length) def __reversed__ (self ): return self.CardDeckIterator(self.length, reverse=True ) class CardDeckIterator : def __init__ (self, length, reverse=False ): self.length = length self.i = 0 self.reverse = reverse def __iter__ (self ): return self def __next__ (self ): if self.i < self.length: if self.reverse: index = self.length - 1 - self.i else : index = self.i suit = _SUITS[index // len (_RANKS)] rank = _RANKS[index % len (_RANKS)] self.i += 1 return Card(rank, suit) else : raise StopIteration deck = CardDeck() for card in reversed (deck): print(card)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from typing import Selfclass Fruit : def __init__ (self, *, name: str , grams: float ) -> None : self.name = name self.grams = grams def __format__ (self, format_spec: str ) -> str: match format_spec: case "kg" : return f"{self.grams / 1000 :.2 f} kg" case "lb" : return f"{self.grams / 453.5924 :.2 f} lb" case "desc" : return f"{self.grams} g of {self.name} " case _: raise ValueError("Unknown format specifier..." ) def __eq__ (self, other: Self ) -> bool: return self.__dict__ == other.__dict__ def __or__ (self, other: Self ) -> Self: new_name: str = f"{self.name} & {other.name} " new_grams: float = self.grams + other.grams return Fruit(name=new_name, grams=new_grams) def __str__ (self ) -> str: return f"Fruit(name={self.name} , grams={self.grams} )" print(f"{f1:kg} " ) print(f"{f1:lb} " ) print(f"{f1:desc} " ) f1 = Fruit(name="Apple" , grams=1200 ) f2 = Fruit(name="Apple" , grams=1200 ) print(f1 == f2) f3 = Fruit(name="Orange" , grams=2200 ) print(f1 | f3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from datetime import dateclass Person : def __init__ (self, name, dob ): self.name = name self.dob = dob def __repr__ (self ): print("__repr__ called..." ) return f"Person(name={self.name} , dob={self.dob.isoformat()} )" def __str__ (self ): print("__str__ called..." ) return f"Person({self.name} )" def __format__ (self, date_format_spec ): print(f"__format__ called with {repr (date_format_spec)} ..." ) dob = format (self.dob, date_format_spec) return f"Person(name={self.name} , dob={dob} )" p = Person("Alex" , date(1900 , 10 , 20 )) print(format (p, "%B %d, %Y" ))
# __sub__通过定义 __sub__ 方法可以给类型添加 - 操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 a = [1 , 2 , 3 ] b = [2 , 3 , 4 ] print(a + b) class SubList (list def __sub__ (self, b ): a = self[:] b = b[:] while len (b) > 0 : ele = b.pop() if ele in a: a.remove(ele) return a al = SubList(a) bl = SubList(b) print(al - bl)
# __call__1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import randomfrom time import sleep, perf_counterfrom functools import wrapsdef profiler (fn ): _counter = 0 _total_elapsed = 0 _avg_time = 0 @wraps(fn ) def inner (*args, **kwargs ): nonlocal _counter nonlocal _total_elapsed nonlocal _avg_time _counter += 1 start = perf_counter() result = fn(*args, **kwargs) end = perf_counter() _total_elapsed += end - start return result def counter (): return _counter def avg_time (): return _total_elapsed / _counter inner.counter = counter inner.avg_time = avg_time return inner @profiler def fn (a, b ): sleep(random.random()) return a, b print(fn(1 , 2 )) print(fn(3 , 4 )) print(fn.counter(), fn.avg_time())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import randomfrom time import sleep, perf_counterclass Profiler : def __init__ (self, fn ): self.counter = 0 self.total_elapsed = 0 self.fn = fn def __call__ (self, *args, **kwargs ): self.counter += 1 start = perf_counter() result = self.fn(*args, **kwargs) end = perf_counter() self.total_elapsed += end - start return result @property def avg_time (self ): return self.total_elapsed / self.counter @Profiler def fn (a, b ): sleep(random.random()) return a, b print(fn(1 , 2 )) print(fn(3 , 4 )) print(fn.counter, fn.avg_time)
# MethodType1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from types import MethodTypeclass Person : def __init__ (self, name ): self.name = name def say_hello (self ): return f"{self.name} says hello!" person = Person("Eric" ) print(say_hello) print(say_hello(person)) person_say_hello = MethodType(say_hello, person) print(person_say_hello) print(person_say_hello()) print(person.__init__)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from types import MethodTypeclass Person : def __init__ (self, name ): self.name = name def register_do_work (self, func ): setattr (self, "_do_work" , MethodType(func, self)) def do_work (self ): do_work_method = getattr (self, "_do_work" , None ) if do_work_method: return do_work_method() else : raise AttributeError("You must first register a do_work method" ) def work_math (self ): return f"{self.name} will teach differentials today." math_teacher = Person("Eric" ) math_teacher.register_do_work(work_math) print(math_teacher.do_work())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import mathclass_name = "Circle" class_body = """ def __init__(self, x, y, r): self.x = x self.y = y self.r = r def area(self): return math.pi * self.r ** 2 """ class_bases = () class_dict = {} exec(class_body, globals (), class_dict) print(class_dict) Circle = type (class_name, class_bases, class_dict) print(Circle) print(type (Circle)) print(Circle.__dict__) circle = Circle(0 , 0 , 1 ) print(circle.x, circle.y, circle.r, circle.area())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import mathclass CustomType (type def __new__ (cls, name, bases, class_dict ): print("Customized type creation!" ) cls_obj = super ().__new__( cls, name, bases, class_dict ) cls_obj.circ = ( lambda self: 2 * math.pi * self.r ) return cls_obj class_body = """ def __init__(self, x, y, r): self.x = x self.y = y self.r = r def area(self): return math.pi * self.r ** 2 """ class_dict = {} exec(class_body, globals (), class_dict) print(class_dict) Circle = CustomType("Circle" , (), class_dict) print(Circle) print(type (Circle)) c = Circle(0 , 0 , 1 ) print(c.area(), c.circ())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import mathclass CustomType (type def __new__ (cls, name, bases, class_dict ): print(f"Using custom metaclass {cls} to create class {name} " ) cls_obj = super ().__new__(cls, name, bases, class_dict) cls_obj.circ = lambda self: 2 * math.pi * self.r return cls_obj class Circle (metaclass=CustomType ): def __init__ (self, x, y, r ): self.x = x self.y = y self.r = r def area (self ): return math.pi * self.r**2 c = Circle(0 , 0 , 1 ) print(c.area(), c.circ())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from functools import wrapsdef func_logger (fn ): @wraps(fn ) def inner (*args, **kwargs ): result = fn(*args, **kwargs) print(f"log: {fn.__qualname__} ({args} , {kwargs} ) = {result} " ) return result return inner class Person : @func_logger def __init__ (self, name, age ): self.name = name self.age = age @func_logger def greet (self ): return f"Hello, my name is {self.name} and I am {self.age} " p = Person("John" , 78 ) print(p.greet()) def class_logger (cls ): for name, obj in vars (cls).items(): if callable (obj): print("decorating:" , cls, name) setattr (cls, name, func_logger(obj)) return cls @class_logger class Person : def __init__ (self, name, age ): self.name = name self.age = age def greet (self ): return f"Hello, my name is {self.name} and I am {self.age} " p = Person("John" , 78 ) print(p.greet())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 import inspectfrom functools import wrapsdef func_logger (fn ): @wraps(fn ) def inner (*args, **kwargs ): result = fn(*args, **kwargs) print(f"log: {fn.__qualname__} ({args} , {kwargs} ) = {result} " ) return result return inner def class_logger (cls ): for name, obj in vars (cls).items(): if isinstance (obj, staticmethod ): original_func = obj.__func__ print("decorating static method" , original_func) decorated_func = func_logger(original_func) method = staticmethod (decorated_func) setattr (cls, name, method) elif isinstance (obj, classmethod ): original_func = obj.__func__ print("decorating class method" , original_func) decorated_func = func_logger(original_func) method = classmethod (decorated_func) setattr (cls, name, method) elif isinstance (obj, property ): print("decorating property" , obj) if obj.fget: obj = obj.getter(func_logger(obj.fget)) if obj.fset: obj = obj.setter(func_logger(obj.fset)) if obj.fdel: obj = obj.deleter(func_logger(obj.fdel)) setattr (cls, name, obj) elif inspect.isroutine(obj): print("decorating:" , cls, name) setattr (cls, name, func_logger(obj)) return cls @class_logger class MyClass : def __init__ (self ): print("__init__ called..." ) @staticmethod def static_method (): print("static method called..." ) @classmethod def cls_method (cls ): print("class method called..." ) def inst_method (self ): print("instance method called..." ) @property def name (self ): print("name getter called..." ) def __add__ (self, other ): print("__add__ called..." ) @class_logger class Other : def __call__ (self ): print(f"{self} .__call__ called..." ) other = Other() my_class = MyClass() my_class.inst_method() MyClass.static_method()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 class Logger : def __init__ (self, fn ): self.fn = fn def __call__ (self, *args, **kwds ): print(f"Log: {self.fn.__name__} called." ) return self.fn(*args, **kwds) class Person : def __init__ (self, name ): self.name = name @Logger def say_hello (self ): return f"{self.name} says hello!" p = Person("David" ) print(p.say_hello) from types import MethodTypeclass Logger : def __init__ (self, fn ): self.fn = fn def __call__ (self, *args, **kwargs ): print(f"Log: {self.fn.__name__} called." ) return self.fn(*args, **kwargs) def __get__ (self, instance, owner_class ): print(f"__get__ called: self={self} , instance={instance} " ) if instance is None : print("\treturning self unbound..." ) return self else : print("\treturning self as a method bound to instance" ) return MethodType(self, instance) class Person : def __init__ (self, name ): self.name = name @Logger def say_hello (self ): return f"{self.name} says hello!" p = Person("David" ) print(p.say_hello) print(p.say_hello()) @Logger def say_bye (): pass say_bye() class Person : @classmethod @Logger def cls_method (cls ): print("class method called..." ) @staticmethod @Logger def static_method (): print("static method called..." ) @Logger def cls_method2 (): print("class method called..." ) Person.cls_method() Person.static_method() Person.cls_method2()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 from functools import wrapsdef func_logger (fn ): @wraps(fn ) def inner (*args, **kwargs ): result = fn(*args, **kwargs) print(f"log: {fn.__qualname__} ({args} , {kwargs} ) = {result} " ) return result return inner def class_logger (cls ): for name, obj in vars (cls).items(): if callable (obj): print("decorating:" , cls, name) setattr (cls, name, func_logger(obj)) return cls @class_logger class Person : def __init__ (self, name, age ): self.name = name self.age = age def greet (self ): return f"Hello, my name is {self.name} and I am {self.age} " Person("Alex" , 10 ).greet() class Student (Person ): def __init__ (self, name, age, student_number ): super ().__init__(name, age) self.student_number = student_number def study (self ): return f"{self.name} studies..." Student("Alex" , 19 , "001" ).study() class ClassLogger (type def __new__ (mcls, name, bases, class_dict ): new_cls = super ().__new__(mcls, name, bases, class_dict) for key, obj in vars (new_cls).items(): if callable (obj): setattr (new_cls, key, func_logger(obj)) return new_cls class Person (metaclass=ClassLogger ): def __init__ (self, name, age ): self.name = name self.age = age def greet (self ): return f"Hello, my name is {self.name} and I am {self.age} " Person("John" , 78 ).greet() class Student (Person ): def __init__ (self, name, age, student_number ): super ().__init__(name, age) self.student_number = student_number def study (self ): return f"{self.name} studies..." Student("Alex" , 19 , "001" ).study()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class AutoClassAttrib (type def __new__ (cls, name, bases, cls_dict, extra_attrs=None ): new_cls = super ().__new__(cls, name, bases, cls_dict) if extra_attrs: print("Creating class with some extra attributes: " , extra_attrs) for attr_name, attr_value in extra_attrs: setattr (new_cls, attr_name, attr_value) return new_cls class Account ( metaclass=AutoClassAttrib, extra_attrs=[("account_type" , "Savings" "apr" , 0.5 pass print(vars (Account)) class AutoClassAttrib (type def __new__ (cls, name, bases, cls_dict, **kwargs ): new_cls = super ().__new__(cls, name, bases, cls_dict) if kwargs: print("Creating class with some extra attributes: " , kwargs) for attr_name, attr_value in kwargs.items(): setattr (new_cls, attr_name, attr_value) return new_cls class Account (metaclass=AutoClassAttrib, account_type="Savings" , apr=0.5 ): pass print(vars (Account))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 class MyMeta (type def __new__ (mcls, name, bases, cls_dict, **kwargs ): print("MyMeta.__new__ called..." ) print("\tcls: " , mcls, type (mcls)) print("\tname:" , name, type (name)) print("\tbases: " , bases, type (bases)) print("\tcls_dict:" , cls_dict, type (cls_dict)) print("\tkwargs:" , kwargs) return super ().__new__(mcls, name, bases, cls_dict) class MyClass (metaclass=MyMeta ): pass class MyMeta (type @staticmethod def __prepare__ (name, bases, **kwargs ): print("MyMeta.__prepare__ called..." ) print("\tname:" , name) print("\tkwargs:" , kwargs) kwargs["kw1" ] = 100 kwargs["kw3" ] = 300 return kwargs def __new__ (mcls, name, bases, cls_dict, **kwargs ): print("MyMeta.__new__ called..." ) print("\tcls: " , mcls, type (mcls)) print("\tname:" , name, type (name)) print("\tbases: " , bases, type (bases)) print("\tcls_dict:" , cls_dict, type (cls_dict)) print("\tkwargs:" , kwargs) return super ().__new__(mcls, name, bases, cls_dict) class MyClass (metaclass=MyMeta, kw1=10 , kw2=20 ): pass print(vars (MyClass)) my_class = MyClass() print(my_class.kw1, my_class.kw2, my_class.kw3) class CustomDict (dict def __setitem__ (self, key, value ): print(f"Setting {key} = {value} in custom dictionary" ) super ().__setitem__(key, value) def __getitem__ (self, key ): print(f"Getting {key} from custom dictionary" ) return int (super ().__getitem__(key)) class MyMeta (type def __prepare__ (name, bases ): return CustomDict() def __new__ (mcls, name, bases, cls_dict ): print("metaclass __new__ called..." ) print(f"\ttype(cls_dict) = {type (cls_dict)} " ) print(f"\tcls_dict={cls_dict} " ) class MyClass (metaclass=MyMeta ): pass
# Default Attribute Lookup1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @startuml Python Default Attribute Lookup Activity Diagram(Flow Chart) ' !theme sketchy ' !theme aws-orange !theme materia start :obj.attr; :obj.~__getattribute__("attr")\ncan override; if (in class or parents' class dict?) then (yes) if (data descriptor?) then (yes) :~__get__; else (no) if (in instance dict?) then (yes) :return it; else (no) if (non-data descriptor?) then (yes) :~__get__; else (no) :return class attr; endif endif endif else (no) if (in instance dict?) then (yes) :return it; else (no) if (override ~__getattr__) then (yes) :return ~__getattr__ result; else (no) :AttributeError; endif endif endif stop @enduml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 class Person : pass p = Person() try : print(p.name) except AttributeError as ex: print("AttributeError" , ex) class Person : def __getattr__ (self, name ): print(f"__getattribute__ did not find {name} " ) return "not found" p = Person() print(p.name) class Person : def __init__ (self, age ): self._age = age def __getattr__ (self, name ): print(f"Could not find {name} " ) alt_name = "_" + name try : return super ().__getattribute__(alt_name) except AttributeError: raise AttributeError(f"Could not find {name} or {alt_name} " ) p = Person(10 ) print(p.age) class DefaultClass : def __init__ (self, attribute_default=None ): self._attribute_default = attribute_default def __getattr__ (self, name ): print(f"{name} not found. creating it and setting it to default..." ) setattr (self, name, self._attribute_default) return self._attribute_default d = DefaultClass("NotAvailable" ) print(d.name) class Person (DefaultClass ): def __init__ (self, name ): super ().__init__("Unavailable" ) self.name = name p = Person("Raymond" ) print(p.name) print(p.age) class AttributeNotFoundLogger : def __getattr__ (self, name ): err_msg = f"'{type (self).__name__} ' object has no attribute '{name} '" print(f"Log: {err_msg} " ) raise AttributeError(err_msg) class Person (AttributeNotFoundLogger ): def __init__ (self, name ): self.name = name p = Person("Raymond" ) try : p.age except AttributeError as ex: print(f"AttributeError raised: {ex} " )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 class Person : def __init__ (self, name, age ): self._name = name self._age = age def __getattribute__ (self, name: str ): if name.startswith("_" ): raise AttributeError(f"Forbidde access to {name} " ) return super ().__getattribute__(name) p = Person("Alex" , 19 ) try : print(p._name) except AttributeError as ex: print(ex) class Person : def __init__ (self, name, age ): self._name = name self._age = age def __getattribute__ (self, name: str ): if name.startswith("_" ) and not name.startswith("__" ): raise AttributeError(f"Forbidde access to {name} " ) return super ().__getattribute__(name) p = Person("Eric" , 78 ) print(p.__dict__) class Person : def __init__ (self, name, age ): self._name = name self._age = age def __getattribute__ (self, name ): if name.startswith("_" ) and not name.startswith("__" ): raise AttributeError(f"Forbidden access to {name} " ) return super ().__getattribute__(name) @property def name (self ): return self._name @property def age (self ): return self._age p = Person("Babb" , 42 ) try : p.name except AttributeError as ex: print(ex) class Person : def __init__ (self, name, age ): self._name = name self._age = age def __getattribute__ (self, name ): if name.startswith("_" ) and not name.startswith("__" ): raise AttributeError(f"Forbidden access to {name} " ) return super ().__getattribute__(name) @property def name (self ): return super ().__getattribute__("_name" ) @property def age (self ): return super ().__getattribute__("_age" ) p = Person("Babb" , 42 ) print(p.name, p.age) class MetaLogger (type def __getattribute__ (self, name ): print("class __getattribute__ called..." ) return super ().__getattribute__(name) def __getattr__ (self, name ): print("class __getattr__ called..." ) return "Not Found" class Account (metaclass=MetaLogger ): apr = 10 print(Account.apr) print(Account.apy) class MyClass : def __getattribute__ (self, name ): print(f"__getattribute__ called... for {name} " ) return super ().__getattribute__(name) def __getattr__ (self, name ): print(f"__getattr__ called... for {name} " ) raise AttributeError(f"{name} not found" ) def say_hello (self ): return "hello" m = MyClass() print(m.say_hello())
# Attribute Set1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class Person : def __setattr__ (self, name, value ) -> None : print("setting instance attribute..." ) super ().__setattr__(name, value) p = Person() p.name = "Babb" Person.class_attr = "test" class MyMeta (type def __setattr__ (self, name, value ) -> None : print("setting class attribute..." ) return super ().__setattr__(name, value) class Person (metaclass=MyMeta ): def __setattr__ (self, name, value ) -> None : print("setting instance attribute..." ) super ().__setattr__(name, value) Person.class_attr = "test" class MyNonDataDesc : def __get__ (self, instance, owner_class ): print("__get__ called on non-data descriptor..." ) class MyDataDesc : def __set__ (self, instance, value ): print("__set__ called on data descriptor..." ) def __get__ (self, instance, owner_class ): print("__get__ called on data descriptor..." ) class MyClass : non_data_desc = MyNonDataDesc() data_desc = MyDataDesc() def __setattr__ (self, name, value ): print("__setattr__ called..." ) super ().__setattr__(name, value) m = MyClass() print(m.__dict__) m.data_desc = 100 m.non_data_desc = 200 print(m.__dict__) m.data_desc m.non_data_desc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class MyClass : def __setattr__ (self, name, value ): print("__setattr__ called..." ) if name.startswith("_" ) and not name.startswith("__" ): raise AttributeError("Sorry, this attribute is read-only." ) setattr (self, name, value) m = MyClass() try : m._test = "test" except AttributeError as ex: print(ex) class MyClass : def __setattr__ (self, name, value ): print("__setattr__ called..." ) if name.startswith("_" ) and not name.startswith("__" ): raise AttributeError("Sorry, this attribute is read-only." ) super ().__setattr__(name, value) m = MyClass() m.test = "test" print(m.__dict__)
# Fun# nonlocal1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def outer (): message = 'local' def inner (): message = 'nonlocal' print("inner:" , message) inner() print("outer:" , message) outer() def outer (): message = 'local' def inner (): nonlocal message message = 'nonlocal' print("inner:" , message) inner() print("outer:" , message) outer()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 x = 100 def outer_func (): x = "hello" def inner_func1 (): nonlocal x x = "python" def inner_func2 (): global x x = "python!!!" print("inner(before)" , x) inner_func2() print("inner(after)" , x) inner_func1() print("outer_func" , x) outer_func() print(x)
# imp如果你的模块不在 sys.path,可以使用 imp 模块中的方法 imp.load_source.
1 2 3 4 5 6 7 8 import impimp.load_source("hi" , "C://data/hi.py" ) import hiimp.load_source("hello" , "C://data/hi.py" ) import hello
Replace imp.load_source() in python 3.12.
1 2 3 4 5 6 7 8 9 10 11 12 import importlib.utilimport importlib.machinerydef load_source (modname, filename ): loader = importlib.machinery.SourceFileLoader(modname, filename) spec = importlib.util.spec_from_file_location(modname, filename, loader=loader) module = importlib.util.module_from_spec(spec) loader.exec_module(module) return module
# fun __code__函数是一个对象, 对象有自己的作用域, 即命名空间,每个命名空间对应一个 __code__ ,包含对象的相关信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def fun (a, b, c, *d, e, f ): localvar = 1 print(dir (fun.__code__)) print('co_argcount:' ,fun.__code__.co_argcount) print('co_kwonlyargcount:' ,fun.__code__.co_kwonlyargcount) print('all_local:' ,fun.__code__.co_nlocals) print('consts:' ,fun.__code__.co_consts) print('filename:' ,fun.__code__.co_filename) print('name:' ,fun.__code__.co_name) print('func_lineno:' ,fun.__code__.co_firstlineno)
# freevars1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def make_averager (): series = [] def averager (new_value ): series.append(new_value) total = sum (series) return total / len (series) return averager avg = make_averager() print(avg.__code__.co_freevars) print(avg.__code__.co_varnames) print(avg.__closure__) print(avg.__closure__[0 ].cell_contents) avg(10 ) avg(11 ) print(avg.__closure__[0 ].cell_contents) def make_averager_nonlocal (): count = 0 sum = 0 def averager (new_value ): nonlocal count nonlocal sum count += 1 sum += new_value return sum / count return averager print(make_averager_nonlocal().__code__.co_freevars)
# closureA Closure is a function object that remembers values in enclosing scopes even if they are not present in memory.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 number = 100 lst = [] for number in range (5 ): lst.append(number) print(number) number = 100 lst = [number**2 for number in range (5 )] print(number) number = 100 [number * i for i in range (5 )] print("i" in globals ()) fns = [] for i in range (4 ): fns.append(lambda x: x**i) print("i" in globals (), i) print(fns[0 ](10 ), fns[1 ](10 )) i = 10 print(fns[0 ](10 ), fns[1 ](10 )) fns = [] def func (x ): return x**i for i in range (4 ): fns.append(func) print(fns[0 ](10 ), fns[1 ](10 )) print(fns[0 ].__closure__, fns[0 ].__code__.co_freevars) def fns (): fns = [] for i in range (4 ): fns.append(lambda x: x**i) return fns fns = fns() print(fns[0 ](10 ), fns[1 ](10 )) print( fns[0 ].__closure__, fns[0 ].__code__.co_freevars ) fns = [lambda x: x**i for i in range (4 )] print(fns[0 ](10 ), fns[1 ](10 )) print( fns[0 ].__closure__, fns[0 ].__code__.co_freevars )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from datetime import datetimedef log (msg, current=datetime.now( ): print(msg, current) log("a" ) log("b" ) fns = [lambda x, p=i: x**p for i in range (4 )] print(fns[0 ](10 ), fns[1 ](10 )) print(fns[0 ].__closure__, fns[0 ].__code__.co_freevars)
# switch case1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def foo (var ): return { 'a' : 1 , 'b' : 2 , 'c' : 3 , }.get(var, 0 ) print(foo('d' )) def foo (var, x ): return { 'a' : lambda x: x+1 , 'b' : lambda x: str (x+2 )+var, 'c' : lambda x: x+3 , }[var](x) print(foo('b' , 2 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def dow_switch_dict (dow ): dow_dict = { 1 : lambda : print("Monday" ), 2 : lambda : print("Tuesday" ), 3 : lambda : print("Wednesday" ), 4 : lambda : print("Thursday" ), 5 : lambda : print("Friday" ), 6 : lambda : print("Saturday" ), 7 : lambda : print("Sunday" ), "default" : lambda : print("Invalid day of week" ), } return dow_dict.get(dow, dow_dict["default" ])() dow_switch_dict(1 ) dow_switch_dict(100 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 def switcher (fn ): registry = dict () registry["default" ] = fn def register (case ): def inner (fn ): registry[case] = fn return fn return inner def decorator (case ): fn = registry.get(case, registry["default" ]) return fn() decorator.register = register return decorator @switcher def dow (): print("Invalid day of week" ) @dow.register(1 def _ (): print("Monday" ) dow.register(2 )(lambda : print("Tuesday" )) dow.register(3 )(lambda : print("Wednesday" )) dow.register(4 )(lambda : print("Thursday" )) dow.register(5 )(lambda : print("Friday" )) dow.register(6 )(lambda : print("Saturday" )) dow.register(7 )(lambda : print("Sunday" )) dow(1 ) dow(2 ) dow(100 )
# insepect打印源码,获得定义模块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import inspectprint(inspect.getsource(inspect.getsource)) print(inspect.getmodule(inspect.getmodule)) print(inspect.currentframe().f_lineno) 👍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import inspectdef func (): pass class MyClass : def func (self ): pass obj = MyClass() print( inspect.isfunction(obj.func), inspect.ismethod(obj.func), inspect.isroutine(obj.func), inspect.isfunction(func), inspect.ismethod(func), inspect.isroutine(func), )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import inspectfrom functools import wrapsclass MyClass : @staticmethod def static_method (): pass @classmethod def cls_method (cls ): pass def inst_method (self ): pass @property def name (self ): pass def __add__ (self, other ): pass class Other : def __call__ (self ): pass other = Other() keys = ( "static_method" , "cls_method" , "inst_method" , "name" , "__add__" , "Other" , "other" , ) inspect_funcs = ( "isroutine" , "ismethod" , "isfunction" , "isbuiltin" , "ismethoddescriptor" , ) max_header_length = max (len (key) for key in keys) max_fname_length = max (len (func) for func in inspect_funcs) print( format ("" , f"{max_fname_length} s" ), "\t" .join(format (key, f"{max_header_length} s" ) for key in keys), ) for inspect_func in inspect_funcs: fn = getattr (inspect, inspect_func) inspect_results = ( format (str (fn(MyClass.__dict__[key])), f"{max_header_length} s" ) for key in keys ) print(format (inspect_func, f"{max_fname_length} s" ), "\t" .join(inspect_results)) print(inspect.ismethod(MyClass.inst_method)) print(inspect.ismethod(MyClass().inst_method))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import inspectdef func ( a: str , b: "int > 0" = 1 , *args: "some extra positioal args" , k1: "keyword-only arg 1" , k2: "keyword-only arg 2" , **kwargs: "some extra keyword-only args" , None ": print(a, b, args, k1, k2, kwargs) for param in inspect.signature(func).parameters.values(): print("Name:" , param.name, end=", " ) print("Default:" , param.default, end=", " ) print("Annotation:" , param.annotation, end=", " ) print("Kind:" , param.kind)
# compile to pyc1 2 3 4 5 6 7 8 9 import py_compilepy_compile.compile (file) import compileallcompileall.compile_dir(dir )
# tracebacktraceback.print_exc() 可以打印出错误堆栈信息,可以显示错误行号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 try : 1 / 0 except Exception as e: print(e) import tracebacktry : 1 / 0 except Exception as e: print(traceback.format_exc())
# decoratorwraps(func) 可以保持原函数的状态, 如果没有添加此段,返回的是包装函数的状态, whatIsLiving.__doc__ 返回 None, whatIsLiving.__name__ 返回 living
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from functools import wrapsdef thisIsLiving (func ): @wraps(func ) def living (*args,**kwargs ): return func(*args,**kwargs) + "living is sleep and eat" return living @thisIsLiving def whatIsLiving (): ''' 什么是活着 ''' return "what is living? " print(whatIsLiving.__doc__) print(whatIsLiving.__name__) print(whatIsLiving())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import functoolsimport timedef decorator (func ): def wrapper (*args, **kwargs ): start_time = time.time() result = func(*args, **kwargs) end_time = time.time() print(f"{func.__name__} execution time: {end_time - start_time} " ) return result return wrapper @decorator def square (x ): return x * x print(square(2 )) def timer (threshold ): def decorator (func ): @functools.wraps(func ) def wrapper (*args, **kwargs ): start_time = time.time() result = func(*args, **kwargs) end_time = time.time() if end_time - start_time > threshold: print( f"{func.__name__} execution time {end_time - start_time} took long than {threshold} " ) return result return wrapper return decorator @timer(1 def sleep_2seconds (): time.sleep(2 ) sleep_2seconds() print(sleep_2seconds.__name__)
decorator_factory with parameter and return decorator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def decorator_factory (a, b ): print("running decorator_factory" ) def decorator (fn ): print("running decorator" ) def inner (*args, **kwargs ): print("running inner" ) print(f"{a=} , {b=} " ) return fn(*args, **kwargs) return inner return decorator @decorator_factory(10 , 20 def func (): print("running func" ) func()
class decorator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class MyClass : def __init__ (self, a, b ): self.a = a self.b = b def __call__ (self, fn ): def inner (*args, **kwargs ): print("decorated function called: a={0}, b={1}" .format (self.a, self.b)) return fn(*args, **kwargs) return inner @MyClass(10 , 20 def my_func (s ): print("hello {0}" .format (s)) my_func("World" )
decorate class
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import mathdef complete_ordering (cls ): if "__eq__" in dir (cls) and "__lt__" in dir (cls): cls.__le__ = lambda self, other: self < other or self == other cls.__gt__ = lambda self, other: not (self < other) and not (self == other) cls.__ge__ = lambda self, other: not (self < other) return cls @complete_ordering class Point : def __init__ (self, x, y ): self.x = x self.y = y def __abs__ (self ): return math.sqrt(self.x**2 + self.y**2 ) def __repr__ (self ): return "Point({0},{1})" .format (self.x, self.y) def __eq__ (self, other ): if isinstance (other, Point): return self.x == other.x and self.y == other.y else : return NotImplemented def __lt__ (self, other ): if isinstance (other, Point): return abs (self) < abs (other) else : return NotImplemented p1, p2, p3 = Point(2 , 3 ), Point(2 , 3 ), Point(0 , 0 ) print(p1 <= p2, p1 >= p2, p1 > p3)
# argparseparse command line option.
1 2 3 4 5 6 7 8 9 10 11 12 import argparseparser = argparse.ArgumentParser() parser.add_argument("--h" , help ="This is Hub id" , dest="hub_id" ) parser.add_argument("--t" , help ="This is file type" , dest="file_type" ) args = parser.parse_args() print(args.hub_id, args.file_type)
# rsplitrsplit 从右向左切割,和 spit 类似,rsplit () 默认分隔符为所有空字符,包括空格、换行 (\n)、制表符 (\t) 等。
1 2 3 4 5 6 7 8 9 10 11 s = "this is string example....wow!!!" print(s.rsplit()) print(s.rsplit('i' , maxsplit=2 )) print(s.rsplit('w' )) print(s.rsplit(None , 2 ))
# glob and iglob
glob — Unix style pathname pattern expansion
The glob module finds pathnames using pattern matching rules similar to the Unix shell. No tilde expansion is done, but * , ? , and character ranges expressed with [] will be correctly matched. This is done by using the os.scandir() and fnmatch.fnmatch() functions in concert, and not by actually invoking a subshell.
Note: The pathnames are returned in no particular order. If you need a specific order, sort the results.
Character
Description
Example Pattern
Matches
*Matches zero or more characters in a filename segment.
*.txtfile.txt , data1.txt
?Matches exactly one character in a filename segment.
data?.csvdata1.csv , dataA.csv
[]Matches any single character within the brackets; a hyphen indicates a range.
file[0-9].jpgfile1.jpg , file9.jpg
**Matches any files and zero or more directories when recursive=True is set.
**/*.pyscript.py , src/module.py
iglob
Return an iterator which yields the same values as glob() without actually storing them all simultaneously.
1 2 3 4 5 6 import globg = glob.iglob('*.txt' ) print(g, list (g)) g = glob.iglob('**/*.txt' , recursive=True ) print(list (g))
# keyword argument and keyword-only argumnet在函数 a 中,x 和 y 是位置参数(positional)同时也可以作为关键字参数(keyword),在函数 b, c 中 y 是仅限关键字参数(keword-only)即强制关键字参数,因为在 y 之前存在 * , 需要指明 y 的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def a (x, y ): pass a(1 , 2 ) a(x=1 , y=2 ) def b (x, *, y ): pass b(1 , y=2 ) def c (x, *z, y ): print(x, z, y) c(1 , y=4 ) c(1 , 2 , 3 , y=4 )
# lambda free variablelambda 表达式中的 x 是一个自由变量, 在运行时绑定值,而不是定义时就绑定,这跟函数的默认值参数定义是不同的。因此,在调用 lambda 表达式的时候,x 的值是执行时的值。如果你想让某个匿名函数在定义时就捕获到值,可以将那个参数值定义成默认参数即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 x = 10 a = lambda y: x + y x = 20 b = lambda y: x + y print(a(10 )) print(b(10 )) x = 10 a = lambda y, x=x: x + y x = 20 b = lambda y, x=x: x + y print(a(10 )) print(b(10 )) funcs = [lambda x: x + n for n in range (3 )] for func in funcs: print(func(1 )) funcs = [lambda x, n=n: x + n for n in range (3 )] for func in funcs: print(func(1 ))
# date1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import timenow = time.time() print(now) tl = time.localtime(now) print(tl) date = time.strftime("%Y-%m-%d %H:%M:%S" , tl) print(date) dnow = "2017-10-16 12:34:00" timestamp = time.mktime(time.strptime(dnow, "%Y-%m-%d %H:%M:%S" )) print(timestamp)
# int1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import fractionsimport stringprint(int (True ), int (False )) a = fractions.Fraction(22 , 7 ) print(a, float (a), int (a)) print(int ("101" , 2 ), int ("fF" , 16 )) print(0b101 , 0xFF ) print(bin (5 ), hex (255 )) print(int ("1412" , 5 )) print(232 // 5 , 232 % 5 ) print(46 // 5 , 46 % 5 ) print(9 // 5 , 9 % 5 ) print(1 // 5 , 1 % 5 ) def from_base10 (n, b ): if b < 2 : raise ValueError("Base b must be greater than or equal to 2" ) if n < 0 : raise ValueError("Number n must be greater than or equal to 0" ) if n == 0 : return [0 ] digits = [] while n > 0 : n, m = divmod (n, b) digits.insert(0 , m) return digits print(from_base10(232 , 5 )) def encode (digits, digit_map ): if max (digits) >= len (digit_map): raise ValueError("digit_map is not long enough to encode the digits" ) return "" .join([digit_map[d] for d in digits]) print(encode([15 , 15 ], "0123456789ABCDEF" )) print( string.ascii_letters, len (string.ascii_letters) ) def refrom_base10 (number, base ): digit_map = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" if base < 2 or base > 62 : raise ValueError(f"Invalid base {base} , base must be in [2, 62]" ) sign = -1 if number < 0 else 1 number *= sign digits = from_base10(number, base) encoding = encode(digits, digit_map) if sign == -1 : encoding = "-" + encoding return encoding print(refrom_base10(232 , 5 )) print(refrom_base10(232 , 62 )) print(refrom_base10(1234567890 , 62 ))
# booleanThere are not many values that evaluate to False, except empty values, such as (), [], {}, “”, the number 0, and the value None. And of course the value False evaluates to False.
The following will return False:
1 2 3 4 5 6 7 8 9 10 bool (False )bool (None )bool (0 )bool (0.0 )bool (Decimal(0 ))bool (0 + 0j )bool ("" )bool (())bool ([])bool ({})
One more value, or object in this case, evaluates to False, and that is if you have an object that is made from a class with a __len__ function that returns 0 or False:
1 2 3 4 5 6 7 8 9 class myclass (): def __len__ (self ): return 0 myobj = myclass() print(bool (myobj)) if myobj: print(True )
python xml.etree returns Element object len is 0 if the element’s not has child elements. So don’t use if a: or if not a: to determine if an element exists
1 2 3 4 5 6 7 import xml.etree.ElementTreeconfig = xml.etree.ElementTree.parse('.\cfgEDIASNackFileImporter.xml' ).getroot() receiver = config.find("./Notification/Appender[@Name='MailTest']/Receiver" ) print(len (receiver), boolen(receiver))
1 2 3 4 5 6 7 8 9 <Config > <Notification > <SMTP Server ="xxx.xxx" /> <Appender Name ="MailTest" > <Receiver value ="test@example.com" /> </Appender > </Notification > </Config >
boolean is subclass of int
1 2 3 4 5 6 7 8 9 10 11 print(issubclass (bool , int )) print(isinstance (True , bool ), isinstance (True , int )) print(True == 1 , False == 0 ) print(int (True ), int (False )) print(True > False ) print(True + True + True , (True + True + True ) % 2 , -True , 100 * False ) print(0 or 0 , 0 or 1 , 1 or 0 , 1 or 1 ) print(0 and 0 , 0 and 1 , 1 and 0 , 1 and 1 )
# decimal1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import decimalx = decimal.Decimal("1.25" ) y = decimal.Decimal("1.35" ) print(decimal.getcontext()) with decimal.localcontext() as ctx: ctx.prec = 6 ctx.rounding = decimal.ROUND_HALF_UP print(decimal.getcontext()) print(round (x, 1 )) print(round (y, 1 )) print(round (x, 1 )) print(round (y, 1 )) print(round (1.25 , 1 ), round (1.35 , 1 )) print(round (1.5 ), round (2.5 ))
1 2 3 4 5 6 import sysfrom decimal import Decimala = 3.1415 b = Decimal("3.1415" ) print(sys.getsizeof(a), sys.getsizeof(b))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from decimal import Decimalimport mathimport timedef run_float (n=1 ): a = 3.1415 for _ in range (n): math.sqrt(a) def run_decimal (n=1 ): a = Decimal("3.1415" ) for _ in range (n): a.sqrt() start = time.perf_counter() run_float(10000000 ) end = time.perf_counter() print("float" , end - start) start = time.perf_counter() run_decimal(10000000 ) end = time.perf_counter() print("decimal" , end - start)
# float1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import matha = 0.3 b = 0.1 + 0.1 + 0.1 print(a == b, math.isclose(a, b)) print(format (a, ".25f" ), format (b, ".25f" )) x = 12345678.01 y = 12345678.02 print(math.isclose(x, y, rel_tol=0.01 )) x = 0.01 y = 0.02 print(math.isclose(x, y, rel_tol=0.01 )) x = 0.00000001 y = 0.00000002 print(math.isclose(x, y, rel_tol=0.01 ), math.isclose(x, y, rel_tol=0.01 , abs_tol=0.01 )) x = 0.00000001 y = 0.00000002 a = 12345678.01 b = 12345678.02 print( math.isclose(x, y, rel_tol=0.01 , abs_tol=0.0001 ), math.isclose(a, b, rel_tol=0.01 , abs_tol=0.0001 ), )
1 2 3 print(round (1.5 ), round (2.5 )) print(round (-1.5 ), round (-2.5 ))
# Fraction1 2 3 4 5 6 7 8 9 10 11 12 13 from fractions import Fractionimport mathprint(Fraction(1 ), repr (Fraction(1 ))) print(Fraction(1 , 2 ), Fraction(denominator=2 , numerator=1 )) x = Fraction(math.pi) print(x, x.limit_denominator(10 )) x = Fraction(0.3 ) print(x, x.limit_denominator(10 ))
# timeit1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import timeitTIMES = 10000 SETUP = """ symbols = '$¢£¥€¤' def non_ascii(c): return c > 127 """ def clock (label, cmd ): res = timeit.repeat(cmd, setup=SETUP, number=TIMES) print(label, *('{:.3f}' .format (x) for x in res)) clock('listcomp :' , '[ord(s) for s in symbols if ord(s) > 127]' ) clock('listcomp + func :' , '[ord(s) for s in symbols if non_ascii(ord(s))]' ) clock('filter + lambda :' , 'list(filter(lambda c: c > 127, map(ord, symbols)))' ) clock('filter + func :' , 'list(filter(non_ascii, map(ord, symbols)))' )
# eval功能:将字符串 str 当成有效的表达式来求值并返回计算结果。
语法: eval (source [, globals [, locals]]) -> value
参数:
source:一个 python 表达式或函数 compile () 返回的代码对象。
globals:可选。必须是 dictionary。
ocals:可选。任意 map 对象。
可以把 list, tuple, dict 和 string 相互转化。
1 2 3 4 5 a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]" print(type (a)) b = eval (a) print(type (b))
# uuiduuid: 通用唯一标识符(Universally Unique ID,UUID)
1 2 3 4 5 6 7 8 9 10 11 import uuiduser_id = uuid.uuid4() print(user_id) from datetime import datetimedef next_id (): return '%015d%s000' % (int (time.time() * 1000 ), uuid.uuid4().hex ) print(next_id()) print('%015d' % 10 )
# partial1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from functools import partialr1 = int ("12" ) print(r1, type (r1)) r2 = int ("0101" , base=2 ) print(r2, type (r2)) int2 = partial(int , base=2 ) r3 = int2("0101" ) print(r3, type (r3)) def multiply (a: float , b: float , name: str | None ) -> float: if name is not None : print(f"{name=} ({a=} , {b=} )" ) return a * b double = partial(multiply, 2 , name="Double" ) triple = partial(multiply, b=3 , name="Triple" ) print(double(10 )) print(triple(10 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Partial : def __init__ (self, func, *args ): self._func = func self._args = args def __call__ (self, *args ): return self._func(*self._args, *args) def fn (a, b, c ): return a, b, c partial_fn = Partial(fn, 10 , 20 ) print(partial_fn(30 ))
# base641 2 3 4 5 6 7 8 9 import base64s = 'hello' a = base64.b64encode(s.encode()) print(a) with open ('01.png' , 'rb' ) as r, open ('01.txt' , 'wb' ) as w: base64.encode(r, w)
# sqrt1 2 3 import mathprint(math.sqrt(25 ) == 25 ** 0.5 )
# mod假设 q 是 a、b 相除产生的商 (quotient),r 是相应的余数 (remainder),那么在几乎所有的计算系统中,都满足:a = b x q + r,其中 |r|<|a|。 所以 r = a - (a / b) x b
python 使用 floor 向下整除法
1 2 3 4 print(-17 // 10 , 17 // -10 , -17 // -10 ) print(-17 % 10 , 17 % -10 , -17 % -10 )
JavaScript 使用向上整除法
1 2 console .log(-17 % 10 , 17 % -10 , -17 % -10 );
# max count1 2 3 4 nums = [3 , 3 , 5 , 6 , 5 , 6 , 3 , 2 , 1 , 3 ] most = max (set (nums), key=nums.count) print(most) print(nums.count(3 ))
# reduce1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from functools import reducelst = [5 , 8 , 6 , 10 , 9 ] min = reduce(lambda x, y: x if x < y else y, lst)print(min ) sum = reduce(operator.add, lst)print(sum ) join = reduce(lambda a, b: f"{a} , {b} " , lst) print(join) lst = [0 , "" , None , 100 ] any_true = reduce(lambda a, b: bool (a) or bool (b), lst) print(any_true) all_true = reduce(lambda a, b: bool (a) and bool (b), lst) print(all_true)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from operator import muldef _reduce (fn, sequence ): result = sequence[0 ] for x in sequence[1 :]: result = fn(result, x) return result lst = [1 , 2 , 3 , 4 ] product = _reduce(lambda x, y: x * y, lst) print(product) product = _reduce(mul, lst) print(product)
# empty function body1 2 3 4 5 6 7 8 9 10 11 12 13 14 def fun1 (): pass def fun2 (): ... def fun3 (): raise NotImplementedError("Not Implement func3" ) fun1() fun2() fun3()
# * and / argument* 后面的参数必须使用关键字参数 (Keyword arguments)。
/ 前面的参数必须使用位置参数 (Positional argulemts)。
1 2 3 4 5 6 7 8 9 10 11 12 def test (a, *, b, c ): print(a, b, c) test(1 , b=2 , c=3 ) def work (name: str , /, job: str , *, hours: int ): print(f"{name} is {job} for {hours} hours." ) work("Babb" , job="coding" , hours=10 ) work("Babb" , "coding" , hours=10 )
# argument default value函数参数的默认值是在创建 / 编译时确定不是调用时。如下两次函数调用输出的时间不变。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from datetime import datetimeimport timedef log (msg, current_dt=datetime.now( ): print(msg, current_dt) time.sleep(2 ) print(datetime.now()) log("error" ) time.sleep(2 ) log("warning" )
# * pack unpack1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 print(2 * 3 ) print("ha" * 3 ) print([1 , 2 ] * 3 ) numbers = [1 , 2 , 3 , 4 , 5 ] first, *rest = numbers print(first, rest) def print_args (*args ): print(type (args), args) print_args(1 , 2 , 3 , 4 ) def print_kwargs (**kwargs ): print(type (kwargs), kwargs) print_kwargs(a=1 , b=2 , c=3 ) def greet (name, age ): print(f"hello {name} , you are {age} old." ) person = ("Babb" , 30 ) greet(*person) list1 = [1 , 2 , 3 ] tuple1 = (4 , 5 , 6 ) merged = [*list1, *tuple1] print(merged) def create_profile (name, age, email ): print(f"{name} - {age} - {email} " ) option = {"name" : "Babb" , "age" : 33 , "email" : "babb@example.com" } create_profile(**option) dict1 = {"a" : 1 , "b" : 2 } dict2 = {"c" : 3 , "d" : 4 } merged = {**dict1, **dict2} print(merged)
# with context1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 from contextlib import contextmanagerimport osimport timeclass MyOpen : def __init__ (self, filepath ): print("__init__" ) self.filepath = filepath def __enter__ (self ): print("__enter__" ) return self.filepath def __exit__ (self, exc_type, exc_value, traceback ): print("__exit__" ) if exc_type is ValueError: print("Caught a ValueError" ) return True with MyOpen("test.txt" ) as f: print(f) raise ValueError("A ValueError occured" ) @contextmanager def my_open (filepath ): print("enter" ) try : yield filepath finally : print("exit" ) with my_open("test.txt" ) as f: print(f) @contextmanager def timer (): start = time.time() yield print(f"cost {time.time() - start} " ) with timer(): time.sleep(2 ) @contextmanager def set_temporary_env (**kwargs ): for k, v in kwargs.items(): os.environ[k] = v yield for k, v in kwargs.items(): del os.environ[k] print(os.environ.get("TEST_VAR" )) with set_temporary_env(TEST_VAR="xyz" ): print(os.environ.get("TEST_VAR" )) print(os.environ.get("TEST_VAR" ))
# with conext seed random1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import contextlibimport randomfrom typing import Any, Generator@contextlib.contextmanager def rand_state (seed: int | None = None ) -> Generator: state: tuple [Any, ...] = random.getstate() random.seed(seed) try : yield finally : random.setstate(state) for _ in range (3 ): with rand_state(1 ): print(random.randrange(0 , 100 ), random.randint(0 , 100 ), random.random()) print(random.randrange(0 , 100 ), random.randint(0 , 100 ), random.random())
# walrus operator1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 (a := 1 ) print(a) lst = [1 , 2 , 3 ] if (length := len (lst)) > 0 : print(f"list is not empty, its size is {length} " ) print(length) while (cmd := input ()) != "exit" : print(f"Got input {cmd} " ) lst = [2 , 4 , 6 , 7 , 10 ] is_even = all ((n := i) % 2 == 0 for i in lst) print(n) print(is_even) def get_info (text: str ) -> dict: return { "words" : (words := text.split()), "word count" : len (words), "character count" : len ("" .join(words)) } print(get_info("Hello World" ))
# match case1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 from dataclasses import dataclassdef match_point (point: tuple ): match point: case (0 , 0 ): print("Origin!" ) case (x, 0 ) | (0 , x): print("on axis" ) case (x, y): print(f"{x=} ,{y=} " ) case others: print(f"{others} is not valid point" ) p1 = (0 , 0 ) p2 = (1 , 2 ) p3 = (1 , 2 , 3 ) p4 = (1 , 0 ) match_point(p1) match_point(p2) match_point(p3) match_point(p4) my_tuple = (0 , 0 ) my_list = [0 , 0 ] match my_tuple: case [0 , 0 ]: print("matched" ) match my_tuple: case 0 , 0 : print("matched" ) match my_list: case (0 , 0 ): print("matched" ) match my_list: case tuple ([0 , 0 ]): print("matched" ) case _: print("not matched" ) match my_tuple: case tuple : print("matched" ) def match_quadrant (point ): match point: case (x, y) if x > 0 and y > 0 : print("First quadrant" ) case (x, y) if x < 0 and y > 0 : print("Second quadrant" ) case (x, y) if x < 0 and y < 0 : print("Third quadrant" ) case (x, y) if x > 0 and y < 0 : print("Fourth quadrant" ) case (x, y): print("On axis" ) match_quadrant((1 , 2 )) match_quadrant((-1 , 2 )) match_quadrant((-1 , -2 )) match_quadrant((1 , -2 )) dict_p = {"x" : 0 , "y" : 30 } match dict_p: case {"x" : 0 , "y" : 0 }: print("Origin" ) case {"x" : x, "y" : y}: print(f"{x=} , {y=} " ) match dict_p: case {"x" : 0 }: print("matched" ) class Point : __match_args__ = ("x" , "y" ) def __init__ (self, x, y ): self.x = x self.y = y p = Point(0 , 1 ) match p: case Point(x=0 , y=0 ): print("Origin" ) case Point(x=x, y=y): print(f"{x=} ,{y=} " ) match p: case Point(0 , 0 ): print("Origin" ) case Point(x, y): print(f"{x=} ,{y=} " ) @dataclass class DataPoint : x: int y: int p = DataPoint(0 , 10 ) match p: case Point(0 , 0 ): print("Origin" ) case Point(x, y): print(f"{x=} ,{y=} " )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 symbols = { "F" : "\u2192" , "B" : "\u2190" , "L" : "\u2191" , "R" : "\u2193" , "pick" : "\u2923" , "drop" : "\u2925" } print(symbols) def op (command ): match command: case "move F" : return symbols["F" ] case "move B" : return symbols["B" ] case "move L" : return symbols["L" ] case "move R" : return symbols["R" ] case "pick" : return symbols["pick" ] case "drop" : return symbols["drop" ] case _: raise ValueError(f"{command} does not compute!" ) print([ op("move F" ), op("move F" ), op("move L" ), op("pick" ), op("move R" ), op("move L" ), op("move F" ), op("drop" ), ]) def op (command ): match command: case ["move" , ("F" | "B" | "L" | "R" ) as direction]: return symbols[direction] case "pick" : return symbols["pick" ] case "drop" : return symbols["drop" ] case _: raise ValueError(f"{command} does not compute!" ) print([ op(["move" , "F" ]), op(["move" , "F" ]), op(["move" , "L" ]), op("pick" ), op(["move" , "R" ]), op(["move" , "L" ]), op(["move" , "F" ]), op("drop" ), ]) def op (command ): match command: case ["move" , *directions]: return tuple (symbols[direction] for direction in directions) case "pick" : return symbols["pick" ] case "drop" : return symbols["drop" ] case _: raise ValueError(f"{command} does not compute!" ) print([ op(["move" , "F" , "F" , "L" ]), op("pick" ), op(["move" , "R" , "L" , "F" ]), op("drop" ), ]) def op (command ): match command: case ["move" , *directions] if set (directions) < symbols.keys(): return tuple (symbols[direction] for direction in directions) case "pick" : return symbols["pick" ] case "drop" : return symbols["drop" ] case _: raise ValueError(f"{command} does not compute!" ) print(op(["move" , "F" , "F" , "L" ])) try : op(["move" , "up" ]) except Exception as ex: print(type (ex), ex)
# magic method1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from __future__ import annotationsfrom typing import Listclass ShoppingCart : def __init__ (self, items: List[str ] ): self.items = items def __add__ (self, another_cart: ShoppingCart ) -> ShoppingCart: return ShoppingCart(self.items + another_cart.items) def __str__ (self ) -> str: return f"Cart({self.items} )" def __len__ (self ) -> int: return len (self.items) def __call__ (self, item: str ): self.items.append(item) cart = ShoppingCart(["apple" , "orange" ]) cart("banana" ) print(cart) print(len (cart)) cart = cart + ShoppingCart(["grape" , "peach" ]) print(cart) class add : def __init__ (self, num ): self.num = num def __str__ (self ): return str (self.num) def __add__ (self, other ): return self.num + other def __call__ (self, other ): return add(self.num + other) addTwo = add(2 ) print(addTwo) print(addTwo + 5 ) print(addTwo(3 )) print(addTwo(3 )(5 )) print(add(1 )(2 )(3 )(4 )(5 ))
# unitestbank_account.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import requestsclass BankAccount : def __init__ (self, initial_balance=0 ): if initial_balance < 0 : raise ValueError("Initial balance cannot be negative" ) self.balance = initial_balance def deposit (self, amount ): if amount < 0 : raise ValueError("Deposit amount cannot be negative" ) self.balance += amount def withdraw (self, amount ): if amount < 0 : raise ValueError("Withdraw amount cannot be negative" ) self.balance -= amount def get_interest_rate (self ): url = "" response = requests.get(url) if response.status_code == 200 : return response.json().get("rate" ) else : raise Exception("Failed to fetch interest rate" )
test_bank_account.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import unittestfrom unittest.mock import patchfrom bank_account import BankAccountclass TestBankAccount (unittest.TestCase ): @classmethod def setUpClass (cls ): print("setUpClass" ) @classmethod def tearDownClass (cls ): print("tearDownClass" ) def setUp (self ): self.account = BankAccount(100 ) def tearDown (self ): print("tearDown" ) def test_create_account (self ): self.account = BankAccount(100 ) self.assertIsInstance(self.account, BankAccount) with self.assertRaises(ValueError): BankAccount(-100 ) def test_deposit (self ): self.account = BankAccount(100 ) self.account.deposit(50 ) self.assertEqual( self.account.balance, 150 , msg="Balance should be 100 + 50 after deposit" ) with self.assertRaises( ValueError, msg="Negative deposit should raise ValueError" ): self.account.deposit(-50 ) def test_withdraw (self ): self.account = BankAccount(100 ) self.account.withdraw(50 ) self.assertEqual( self.account.balance, 50 , msg="Balance should be 100 - 50 after withdraw" ) with self.assertRaises( ValueError, msg="Negative withdraw should raise ValueError" ): self.account.deposit(-50 ) def test_get_interest_rate (self ): with patch("bank_account.requests.get" ) as mock_get: mock_get.return_value.status_code = 200 mock_get.return_value.json.return_value = {"rate" : 0.5 } interest_rate = self.account.get_interest_rate() self.assertEqual(interest_rate, 0.5 ) if __name__ == "__main__" : unittest.main()
unittest mock
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from unittest.mock import Mock, MagicMock, patchmock = Mock() mock.get.return_value = "mocked value" print(mock.get()) magic_mock = MagicMock() magic_mock.__str__ = lambda self=magic_mock: "magic mocked value" print(str (magic_mock)) def foo (): return "original value" with patch("__main__.foo" , return_value="patched value" ): print(foo()) with patch("__main__.foo" ) as mock_foo: mock_foo.return_value = "another patched value" print(foo()) @patch("__main__.foo" def test_foo (mock_foo ): mock_foo.return_value = "test patched value" print(foo()) test_foo()
# reference counting1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import sysimport ctypesa = [1 , 2 , 3 , 4 ] b = a print(sys.getrefcount(a)) def ref_count (address: int ): return ctypes.c_long.from_address(address).value print(ref_count(id (a))) b = None print(ref_count(id (a))) a = None print(ref_count(id (a)))
# pre-caculate at compile time1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def func1 (): a = 24 * 60 b = (1 , 2 ) * 5 c = "abc" * 3 d = "abc" * 10000 e = "the quick brown fox " * 5 f = ["a" , "b" ] * 3 print(func1.__code__.co_consts) def func2 (e ): for e in [1 , 2 , 3 ]: pass print(func2.__code__.co_consts) def func3 (e ): for e in {1 , 2 , 3 }: pass print(func3.__code__.co_consts)
# not logic in __main__1 2 3 4 5 6 7 8 def main () -> None : local_a = "a" print(f"{globals ().get("global_a" )} {globals ().get("local_a" )} " ) if __name__ == "__main__" : global_a = "A" main()
# generator typeA generator can be annotated using the generic type Generator[YieldType, SendType, ReturnType]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import sysfrom typing import Generatordef fibonacci_generator () -> Generator[int, None , None ]: a, b = 0 , 1 while True : yield a a, b = b, a + b fib_gen: Generator[int , None , None ] = fibonacci_generator() n: int = 10 line_break: str = "-" * 20 while True : input (f"Tap 'enter' for the next {n} number of fibonacci" ) print(line_break) for _ in range (n): print(next (fib_gen)) print(line_break)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def read (path: str ) -> Generator[str, None , str]: with open (path, "r" ) as file: for line in file: yield line.strip() return "This is end!" reader: Generator[str , None , str ] = read("note.txt" ) input ("Press 'enter'" )while True : try : print(next (reader)) except StopIteration as e: print(e.value) sys.exit() input ()
1 2 3 4 5 6 7 8 9 10 11 12 13 def cumulative_sum () -> Generator[float, float, None ]: total: float = 0 while True : total += yield total cumulative_generator: Generator[float , float , None ] = cumulative_sum() next (cumulative_generator)while True : value: float = float (input ("Enter a value: " )) current_sum: float = cumulative_generator.send(value) print(f"{current_sum=} " )
1 2 3 4 5 6 7 8 9 10 def infinite_repeater (sequence: list [Any] ) -> Generator[Any, None , None ]: while True : for item in sequence: yield item repeater: Generator[Any, None , None ] = infinite_repeater([1 , 2 , 3 , 4 ]) for _ in range (10 ): print(next (repeater))
# methodcaller1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from operator import methodcallerfrom timeit import repeatnames: list [str ] = ["Bob" , "Tom" , "James" , "Sandra" , "Blake" ] start_with_b: methodcaller = methodcaller("startswith" , "B" ) filtered: filter = filter (start_with_b, names) print(list (filtered)) count_a: methodcaller = methodcaller("count" , "a" ) print(list (sorted (names, key=count_a))) warm_up: str = """ for i in range(5): ... """ methodcaller_test: str = """ filter(start_with_b, names) """ lambda_test = """ filter(lambda x: x.startswith("B"), names) """ repeat(stmt=warm_up) methodcaller_time: float = min (repeat(methodcaller_test, globals =globals ())) lambda_time: float = min (repeat(lambda_test, globals =globals ())) print(f"{methodcaller_time=:.5 f} " ) print(f"{lambda_time=:.5 f} " )
# lru_cache1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from functools import lru_cache@lru_cache(maxsize=128 , typed=False ) def add (a, b ): print(f"{a} + {b} = {a + b} " ) return a + b add(1 , 1 ) add(1 , 1 ) add(1.0 , 1.0 ) add(1 , 2 ) add(2 , 1 ) print(add.cache_info()) @lru_cache(maxsize=2 , typed=True ) def add (a, b ): print(f"{a} + {b} = {a + b} " ) return a + b add(1 , 1 ) add(1.0 , 1.0 ) add(1 , 2 ) add(1 , 2 ) add(1 , 1 ) print(add.cache_info()) print(add.cache_clear()) print(add.cache_info())
fibonacci
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from functools import lru_cache@lru_cache def fibonacci (n ): print ('Calculating fibonacci({0})' .format (n)) return 1 if n < 3 else fibonacci(n-1 ) + fibonacci(n-2 ) print(fibonacci(6 )) print(fibonacci(6 )) print(fibonacci(8 ))
simple custom define memolizer like lru_cache
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def memolizer (fn ): cache = dict () def inner (n ): if n not in cache: cache[n] = fn(n) return cache[n] return inner @memolizer def fib (n ): print ('Calculating fib({0})' .format (n)) return 1 if n < 3 else fib(n-1 ) + fib(n-2 ) print(fib(6 )) print(fib(6 ))
simple custom define memolizer using frozenset support order insensitive cache
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from functools import lru_cache@lru_cache def add (a, b ): print("caculating a + b" ) return a + b print(add(a=1 , b=2 )) print(add(b=2 , a=1 )) print(add(a=[1 , 2 , 3 ], b=[4 , 5 , 6 ]))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def memolizer (fn ): cache = {} def inner (*args, **kwargs ): key = frozenset (args) | frozenset (kwargs.items()) if key not in cache: cache[key] = fn(*args, **kwargs) return cache[key] return inner @memolizer def add (a, b ): print("caculating a + b" ) return a + b print(add(a=1 , b=2 )) print(add(b=2 , a=1 )) print(add(1 , 2 )) print(add(2 , 1 ))
cache dict as default parameter
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def factorial (n, cache={} ): if n < 1 : return 1 elif n in cache: return cache[n] else : print(f"caculating {n} " ) result = n * factorial(n - 1 , cache=cache) cache[n] = result return result print(factorial(n=3 )) print(factorial(n=4 ))
# cached_property1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from functools import cached_propertyfrom statistics import meanclass Caculator : def __init__ (self, values: list [float ] ): self.values = values @cached_property def sum (self ) -> float: print(f"Getting the sum of: {self.values} " ) return sum (self.values) @cached_property def average (self ) -> float: print(f"Getting the average of: {self.values} " ) return mean(self.values) numbers: list [float ] = [1.5 , 2.5 , 3.5 , 4.5 , 5.5 ] caculator: Caculator = Caculator(numbers) print(caculator.average) print(caculator.average) print(caculator.average) caculator: Caculator = Caculator(numbers + [6.5 , 7.5 ]) print(caculator.average) print(caculator.average) print(caculator.average)
# singledispatch1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from html import escapedef singledispatch (fn ): registry = dict () registry[object ] = fn def register (type_ ): def inner (fn ): registry[type_] = fn return fn return inner def decorator (arg ): fn = registry.get(type (arg), registry[object ]) return fn(arg) def dispatch (type_ ): return registry.get(type_, registry[object ]) decorator.register = register decorator.registry = registry.keys() decorator.dispatch = dispatch return decorator @singledispatch def htmlize (arg ): return escape(str (arg)) @htmlize.register(float def html_real (a ): return '{0:.2f}' .format (round (a, 2 )) @htmlize.register(str def html_str (s ): return escape(s).replace('\n' , '<br/>\n' ) @htmlize.register(tuple @htmlize.register(list def html_list (l ): items = ['<li>{0}</li>' .format (htmlize(item)) for item in l] return '<ul>\n' + '\n' .join(items) + '\n</ul>' @htmlize.register(dict def html_dict (d ): items = ['<li>{0}={1}</li>' .format (htmlize(k), htmlize(v)) for k, v in d.items()] return '<ul>\n' + '\n' .join(items) + '\n</ul>' print(htmlize.registry) print(htmlize([1 , 2 , 3 ])) print(htmlize("""this is a multi line string with a < 10""" ))
# callable1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 print( callable (print ), callable ("abc" .upper), callable (str .upper), callable (callable ), callable (lambda x: x.upper()), ) class MyClass : def __init__ (self, x=0 ): self.counter = x def __call__ (self, x=1 ): print("update counter" ) self.counter = x a = MyClass() print(callable (MyClass)) print(callable (a))
# operator1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 import operatorprint(dir (operator)) print( operator.add(2 , 3 ), operator.mul(2 , 3 ), operator.truediv(3 , 2 ), operator.floordiv(3 , 2 ), ) print(operator.lt(2 , 3 ), operator.le(2 , 2 )) a = 1 b = a print(operator.is_(a, b)) print(operator.truth([]), operator.truth("abc" )) lst = [1 , 2 , 3 , 4 ] print(operator.getitem(lst, 1 )) operator.setitem(lst, 1 , 100 ) operator.delitem(lst, 3 ) print(lst) lst = [1 , 2 , 3 , 4 ] fun = operator.itemgetter(1 ) print(fun) print(fun(lst), fun("python" )) lst = [1 , 2 , 3 , 4 ] fun = operator.itemgetter(1 , 2 , 3 ) print(fun(lst), fun("python" )) class MyClass : def __init__ (self ): self.a = 1 self.b = 2 self.c = 3 def test (self ): print("test method running" ) obj = MyClass() prop_a = operator.attrgetter("a" ) print(prop_a(obj)) var = "b" print(operator.attrgetter(var)(obj)) a, b, test = operator.attrgetter("a" , "b" , "test" )(obj) print(a, b) test() lst = [5 - 10j , 3 + 3j , 2 - 100j ] sorted_result = sorted (lst, key=operator.attrgetter("real" )) print(sorted_result) lst = [(2 , 3 , 4 ), (1 , 3 , 5 ), (6 ,), (4 , 100 )] sorted_result = sorted (lst, key=lambda x: x[0 ]) print(sorted_result) sorted_result = sorted (lst, key=operator.itemgetter(0 )) print(sorted_result) class MyClass : def __init__ (self ): self.a = 1 self.b = 2 def test (self, c, d, *, e ): print(self.a, self.b, c, d, e) obj = MyClass() fun = operator.attrgetter("test" ) fun(obj)(3 , 4 , e=5 ) operator.methodcaller("test" , 30 , 40 , e=50 )(obj)
# validate arguments provided1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def validate (a=object (object (object ( ): default_a = validate.__defaults__[0 ] default_b = validate.__defaults__[1 ] default_kw = validate.__kwdefaults__["kw" ] if a is not default_a: print("Argument a was provided" ) else : print("Argument a was not provided" ) if b is not default_b: print("Argument b was provided" ) else : print("Argument b was not provided" ) if kw is not default_kw: print("Argument kw was provided" ) else : print("Argument kw was not provided" ) validate(100 , 200 , kw=None ) validate(100 , 200 ) validate()
# reference counting1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import sysimport ctypesa = [1 , 2 , 3 , 4 ] b = a print(sys.getrefcount(a)) def ref_count (address: int ): return ctypes.c_long.from_address(address).value print(ref_count(id (a))) b = None print(ref_count(id (a))) a = None print(ref_count(id (a)))
# pascal triangle1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from math import factorialfrom pprint import pprintdef combination (n, k ): return factorial(n) // (factorial(k) * factorial(n - k)) size = 10 pascal = [[combination(n, k) for k in range (n + 1 )] for n in range (size + 1 )] pprint(pascal)
# Loop# while loop1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 min_length = 2 while True : name = input ("Please enter your name: " ) if len (name) > min_length and name.isprintable() and name.isalpha(): break print("Hello, {0}" .format (name)) lst = [1 , 2 , 3 ] val = 10 idx = 0 while idx < len (lst): if lst[idx] == val: break idx += 1 else : lst.append(val) print(lst)
# for loop1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 s = "hello" i = 0 for c in s: print(i, c) i += 1 s = "hello" for i in range (len (s)): print(i, s[i]) i += 1 s = "hello" for i, c in enumerate (s): print(i, c)
# Exception# try continue/break1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 a = 0 b = 2 while a < 4 : print("-" * 30 ) a += 1 b -= 1 try : _ = a / b except ZeroDivisionError: print(f"{a} , {b} - division by 0" ) continue finally : print(f"{a} , {b} - always executes" ) print(f"{a} , {b} - main loop" ) a = 0 b = 2 while a < 4 : print("-" * 30 ) a += 1 b -= 1 try : a / b except ZeroDivisionError: print(f"{a} , {b} - division by 0" ) break finally : print(f"{a} , {b} - always executes" ) print(f"{a} , {b} - main loop" ) else : print("Code executed without a zero division error" )
### NotImplementedError
1 2 3 4 5 6 7 8 9 10 def scrape_website (url: str ) -> dict: pass scrape_website("www.abc.com" ) def scrape_website (url: str ) -> dict: raise NotImplementedError("Functionality is missing" ) scrape_website("www.abc.com" )
# TypeError and ValueError1 2 3 4 5 6 7 print(int ("10" )) print(int ("x" )) print(int (None ))
# Error to file1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import sysfrom pprint import pprintclass Person : def __del__ (self ): raise ValueError("Something went bump..." ) class ErrToFile : def __init__ (self, fname ): self._fname = fname self._current_stderr = sys.stderr def __enter__ (self ): self._file = open (self._fname, "w" ) sys.stderr = self._file def __exit__ (self, exc_type, exc_value, exc_tb ): sys.stderr = self._current_stderr if self._file: self._file.close() return False p = Person() with ErrToFile("err.txt" ): del p with open ("err.txt" ) as f: pprint(f.readlines()) import sysfrom pprint import pprintclass Person : def __del__ (self ): raise ValueError("Something went bump..." ) class ErrToFile : def __init__ (self, fname ): self._fname = fname self._current_stderr = sys.stderr def __enter__ (self ): self._file = open (self._fname, "w" ) sys.stderr = self._file def __exit__ (self, exc_type, exc_value, exc_tb ): sys.stderr = self._current_stderr if self._file: self._file.close() return False p = Person() with ErrToFile("err.txt" ): del p with open ("err.txt" ) as f: pprint(f.readlines())
# EAFP Easier to ask for forgiveness than permission1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 def get_item_forgive_me (seq, idx, default=None ): try : return seq[idx] except (IndexError, TypeError, KeyError): return default def get_item_ask_perm (seq, idx, default=None ): if hasattr (seq, "__getitem__" ): if idx < len (seq): return seq[idx] return default print(get_item_forgive_me([1 , 2 , 3 ], 0 )) print(get_item_forgive_me([1 , 2 , 3 ], 10 , "Nope" )) print(get_item_ask_perm([1 , 2 , 3 ], 0 )) print(get_item_ask_perm([1 , 2 , 3 ], 10 , "Nope" )) print(get_item_forgive_me({"a" : 100 }, "a" )) def get_item_ask_perm (seq, idx, default=None ): if hasattr (seq, "__getitem__" ): if isinstance (seq, dict ): return seq.get(idx, default) elif isinstance (idx, int ): if idx < len (seq): return seq[idx] return default print(get_item_ask_perm({"a" : 100 }, "a" )) class ConstantSequence : def __init__ (self, val ): self.val = val def __getitem__ (self, idx ): return self.val seq = ConstantSequence(10 ) print(seq[0 ]) print(get_item_forgive_me(seq, 0 , "Nope" ))
# raise exception from ignore trace back1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 try : raise ValueError("level 1" ) except ValueError as ex: try : raise TypeError("level 2" ) except TypeError: raise KeyError("level 3" ) from ex
# API Exception1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 import jsonfrom datetime import datetime, timezonefrom http import HTTPStatusclass APIException (Exception ): """Base API exception""" http_status = HTTPStatus.INTERNAL_SERVER_ERROR internal_err_msg = "API exception occurred." user_err_msg = "We are sorry. An unexpected error occurred on our end." def __init__ (self, *args, user_err_msg=None ): if args: self.internal_err_msg = args[0 ] super ().__init__(*args) else : super ().__init__(self.internal_err_msg) if user_err_msg is not None : self.user_err_msg = user_err_msg def to_json (self ): err_object = {"status" : self.http_status, "message" : self.user_err_msg} return json.dumps(err_object) def log_exception (self ): exception = { "type" : type (self).__name__, "http_status" : self.http_status, "message" : self.args[0 ] if self.args else self.internal_err_msg, "args" : self.args[1 :], } print(f"EXCEPTION: {datetime.now(timezone.utc).isoformat()} : {exception} " ) try : raise APIException() except APIException as ex: ex.log_exception() print(ex.to_json()) class ApplicationException (APIException ): """Indicates an application error (not user caused) - 5xx HTTP type errors""" http_status = HTTPStatus.INTERNAL_SERVER_ERROR internal_err_msg = "Generic server side exception." user_err_msg = "We are sorry. An unexpected error occurred on our end." class DBException (ApplicationException ): """General database exception""" http_status = HTTPStatus.INTERNAL_SERVER_ERROR internal_err_msg = "Database exception." user_err_msg = "We are sorry. An unexpected error occurred on our end." class DBConnectionError (DBException ): """Indicates an error connecting to database""" http_status = HTTPStatus.INTERNAL_SERVER_ERROR internal_err_msg = "DB connection error." user_err_msg = "We are sorry. An unexpected error occurred on our end." class ClientException (APIException ): """Indicates exception that was caused by user, not an internal error""" http_status = HTTPStatus.BAD_REQUEST internal_err_msg = "Client submitted bad request." user_err_msg = "A bad request was received." class NotFoundError (ClientException ): """Indicates resource was not found""" http_status = HTTPStatus.NOT_FOUND internal_err_msg = "Resource was not found." user_err_msg = "Requested resource was not found." class Account : def __init__ (self, account_id, account_type ): self.account_id = account_id self.account_type = account_type class NotAuthorizedError (ClientException ): """User is not authorized to perform requested action on resource""" http_status = HTTPStatus.UNAUTHORIZED internal_err_msg = "Client not authorized to perform operation." user_err_msg = "You are not authorized to perform this request." def lookup_account_by_id (account_id ): if not isinstance (account_id, int ) or account_id <= 0 : raise ClientException( f"Account number {account_id} is invalid." , f"account_id = {account_id} " , "type error - account number not an integer" , ) if account_id < 100 : raise DBConnectionError("Permanent failure connecting to database." , "db=db01" ) elif account_id < 200 : raise NotAuthorizedError( "User does not have permissions to read this account" , f"account_id={account_id} " , ) elif account_id < 300 : raise NotFoundError("Account not found." , f"account_id={account_id} " ) else : return Account(account_id, "Savings" ) def get_account (account_id ): try : account = lookup_account_by_id(account_id) except APIException as ex: ex.log_exception() return ex.to_json() else : return HTTPStatus.OK, {"id" : account.account_id, "type" : account.account_type} get_account("ABC" ) print(get_account(400 ))
# Thread and Coroutine# asyncio.to_thread change sync to async1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import asynciofrom asyncio import Taskimport requestsfrom requests import Responseasync def fetch_status (url: str ) -> dict: print(f"Fetch status for: {url} " ) response: Response = await asyncio.to_thread(requests.get, url, None ) print("Done!" ) return {"status" : response.status_code, "url" : url} async def main () -> None : task_a: Task[dict ] = asyncio.create_task(fetch_status("https://fanyi.sogou.com/" )) task_b: Task[dict ] = asyncio.create_task(fetch_status("https://www.youdao.com/" )) task_a_status: dict = await task_a task_b_status: dict = await task_b print(task_a_status) print(task_b_status) asyncio.run(main=main())
# Regex# re.search() and re.match()re.search() 查找第一个符合条件的,不要求必须是文字开头。re.match() 查找文字开头是否符合条件。
1 2 3 4 5 6 7 8 9 10 11 12 import restring = 'abc1de2f' m = re.search('[0-9]' , string) print(m, m.group()) m = re.match('[0-9]' , string) print(m) m = re.match('[0-9]' , '1abc1de2f' ) print(m, m.group())
# name groupname group: 命名组,可以通过 ?P<name> 给查找到的 group 命名
1 2 3 4 5 6 7 import rem = re.search(r'out_(\d{4})' ,'out_1984.txt' ) print(m.group(0 ), m.group(1 )) m = re.search(r'out_(?P<year>\d{4})' , 'out_1984.txt' ) print(m.group('year' ))
# reference groupreference group: 引用组,可以通过 \n 引用分组,代表引用第 n 个分组。
1 2 3 4 5 import rem = re.match(r"<([a-zA-Z]*)>\w*</\1>" , "<div>Hello</div>" ) print(m.group(), m.group(0 ), m.group(1 ))
# operate sub group1 2 3 4 5 import res = "start TT end" res = re.sub(r"([A-Z])\1" , lambda pat: pat.group(1 ).lower(), s) print(res)
# regex example提取网页中的文字内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import redata_str = """ <div> <p>岗位职责:</p> <p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p> </div> """ print(re.sub(r"<[^>]*>| |\n" , "" , data_str)) print(re.sub(r"<.*?>| |\n" , "" , data_str))
# Web将请求头通过分割转换为列表,再通过 dict(list) 函数将 list 转换为 dict.dict([['Host', 'open.tool.hexun.com']]) => {'Host': 'open.tool.hexun.com'}
1 2 3 4 5 6 7 8 9 10 11 12 13 raw_headers = """Host: open.tool.hexun.com Pragma: no-cache Cache-Control: no-cache User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36 Accept: */* Referer: http://stock.hexun.com/gsxw/ Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8""" headers = dict ([line.split(": " ) for line in raw_headers.split("\n" )]) print(headers)
# request_htmlrequest_html 将获取页面和解析页面内容整合在一起。
1 2 3 4 5 6 7 8 9 10 11 from requests_html import HTMLSessionsession = HTMLSession() r = session.get('https://python.org/' ) print(r.html.links) about = r.html.find('#about' , first=True ) print(about.text) content = r.html.search('python is a {} language' )[0 ] print(content)
# HTMLParser unescape from HTML Entity将 HTML Entity 转换为普通字符
1 2 3 4 5 6 7 8 from html.parser import HTMLParserdef decode_html (input h = HTMLParser() s = h.unescape(input ) return s print(decode_html('and#38451;锟〹<§' ))
# pyppeteer1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import asynciofrom pyppeteer import launchasync def main (): browser = await launch() page = await browser.newPage() await page.goto('http://example.com' ) await page.screenshot({'path' : 'example.png' }) await browser.close() loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait([main()])) loop.close()
# flask index page1 2 3 4 @app.route('/' , methods = ['GET' , 'POST' ] @app.route('/page=<page>' , methods = ['GET' , 'POST' ] def index (page=1 ): pass
# Other# python and python -mpython run.py 是把 run.py 所在的目录放到 sys.path 属性中。
python -m run.py 是把输入命令的目录放到 sys.path 属性中。
# venvpython3 create virtual enviroment.
# share file use mobile and computer
cmd 进入需要共享的文件夹,执行 python -m http.server
ipconfig/all 查看电脑 ip
手机端连接和电脑同一个网段的 wifi,在浏览器输入电脑 ip:port 即可共享文件
# python cProfile
From: Analyzing Slow python Code using cProfile
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from time import sleepimport cProfileimport pstatsprofiler = cProfile.Profile() profiler.enable() def a (): sleep(1 ) b() sleep(1 ) def b (): sleep(1 ) a() profiler.disable() stats = pstats.Stats(profiler) stats.dump_stats("./cProfile.stats" ) stats.print_stats()
$ pip install snakeviz
snakeviz cProfile.stats
# chardet根据文件内容检测编码。
1 2 3 4 5 6 7 8 with open ("chardet_test.py" , "rb" ) as f: file_data = f.read() result = chardet.detect(file_data) print(result) file_content = file_data.decode(encoding=result["encoding" ]) print("-" * 50 ) print(file_content)
# delete bom1 2 3 s = open ('./850_with_bom.json' , mode='r' , encoding='utf-8-sig' ).read() open ('./850.json' , mode='w' , encoding='utf-8' ).write(s)
# windows pip install PermissionErrorPermissionError: [WinError 5] 拒绝访问。
找到 python 安装目录赋予当前用户完全控制的权限。
# windows schedule call python如果没有设置 python 环境变量可以在开始位置写入 python.exe 的路径,如 C:\Program Files\python36
# python run daemon on window1 2 3 4 5 "C:\Program Files\python36\pythonw.exe" test.py"C:\Program Files\python36\pythonw.exe" test.py >log.txt 2 >&1 "C:\Program Files\python36\pythonw.exe" test.py 1 >stdout.txt 2 >stderr.txt
# replace double slash to one slash1 2 3 4 5 6 7 8 9 10 11 12 s = r'foo \\ bar' print(s) print(s.replace('\\\\' , '\\' )) s = 'foo \\\\ bar' print(s) print(s.replace('\\\\' , '\\' ))
# replace normal unicode str to unicode encoded str将普通的 Unicode 字符串转换为 Unicode 编码的字符串。'\\u9500\\u552e' or r'\u9500\u552e'=> '\u9500\u552e'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import jsonimport res = "\\u9500\\u552e" print(s) print("\u9500\u552e" ) s = "\\u9500\\u552e" print(json.loads(f'"{s} "' )) print(s.encode().decode("unicode_escape" ))
# while loop break1 2 3 4 5 6 7 8 9 10 11 12 while True : command = input ('>' ) print('ECHO' , command) if command.lower() == 'quit' : break
# douban pypi1 pip install requests -i https://pypi.douban.com/simple/
# read toml1 2 3 4 5 6 7 8 9 10 11 import tomlfrom pprint import pprint as print def read_toml (file_path ): with open (file_path, "r" ) as f: data = toml.load(f) return data print(read_toml("./config.toml" ))
config.toml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 name = 'Babb' age = 50 sex = "\"Male\"" hobbies = ['reading' , 'coding' , 'gaming' ]birthdate = 1998 -07 -07 T00:00 :00 Zshape = { height = 170 , wiight=60 }[[account]] name = 'bilibili' username = 'babb' password ='xxx' [[account]] name = 'youtube' username = 'babb' password ='xxx'
# json serialize1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import jsond = {"a" : float ("inf" ), "b" : float ("nan" )} s = json.dumps(d) print(s) d = {10 : "int" , 10.5 : "float" , (1 , 1 ): "complex" } s = json.dumps(d, skipkeys=True ) print(s) d = {"name" : "Python" , "age" : 27 , "created_by" : "Guido van Rossum" , "list" : [1 , 2 , 3 ]} s = json.dumps(d) print(s) s = json.dumps(d, indent="--" , separators=(";" , " = " )) print(s)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 from datetime import datetime, UTCimport jsonclass Person : def __init__ (self, name, age ): self.name = name self.age = age def __repr__ (self ): return f"Person(name={self.name} , age={self.age} )" def toJSON (self ): return vars (self) class Point : def __init__ (self, x, y ): self.x = x self.y = y def __repr__ (self ): return f"Point(x={self.x} , y={self.y} )" def custom_json_formatter (arg ): if isinstance (arg, datetime): return arg.isoformat() elif isinstance (arg, set ): return list (arg) else : try : return arg.toJSON() except AttributeError: try : return vars (arg) except TypeError: return str (arg) person = Person("John" , 82 ) point = Point(10 , 10 ) log_record = dict ( message="Create new point" , point=point, created_time=datetime.now(UTC), created_by=person, ) print(json.dumps(log_record, default=custom_json_formatter, indent=2 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 import jsonfrom decimal import Decimalfrom fractions import Fractionfrom datetime import datetime, UTCfrom functools import singledispatchclass Person : def __init__ (self, name, age ): self.name = name self.age = age def __repr__ (self ): return f"Person(name={self.name} , age={self.age} )" def toJSON (self ): return vars (self) class Point : def __init__ (self, x, y ): self.x = x self.y = y def __repr__ (self ): return f"Point(x={self.x} , y={self.y} )" @singledispatch def json_format (arg ): print(arg) try : print("\ttrying to use toJSON()..." ) return arg.toJSON() except AttributeError: print("\tfailed - trying to use vars..." ) try : return vars (arg) except TypeError: print("\tfailed - using string repr..." ) return str (arg) @json_format.register(datetime ) def _ (arg ): return arg.isoformat() @json_format.register(set def _ (arg ): return list (arg) person = Person("John" , 82 ) point = Point(10 , 10 ) log_record = dict ( message="Create new point" , point=point, created_time=datetime.now(UTC), created_by=person, ) print(json.dumps(log_record, default=json_format, indent=2 )) @json_format.register(Decimal ) def _ (arg ): return f"Decimal({str (arg)} )" result = json.dumps( dict ( a=1 + 1j , b=Decimal("0.5" ), c=Fraction(1 , 3 ), p=Person("Python" , 27 ), pt=Point(0 , 0 ), time=datetime.now(UTC), ), default=json_format, indent=2 , ) print(result)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import jsonfrom datetime import datetime, UTCclass CustomEncoder (json.JSONEncoder ): def __init__ (self, *args, **kwargs ): super ().__init__(skipkeys=True , allow_nan=False , indent=2 ) def default (self, arg ): if isinstance (arg, datetime): return dict ( datatype="datetime" , iso=arg.isoformat(), date=arg.date().isoformat(), time=arg.time().isoformat(), year=arg.year, month=arg.month, day=arg.day, hour=arg.hour, minutes=arg.minute, seconds=arg.second, ) else : return super ().default(arg) d = {"time" : datetime.now(UTC), 1 + 1j : "complex" , "name" : "python" } s = json.dumps(d, cls=CustomEncoder) print(s)
serialize date
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import jsonfrom json import JSONEncoderfrom datetime import datetimefrom datetime import datenow = datetime.now() class CustomEncoder (JSONEncoder ): def default (self, obj ): if isinstance (obj, date) or isinstance (obj, datetime): return obj.isoformat() return super ().default(obj) print(json.dumps(now, cls=CustomEncoder))
serialize custom object
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Person : def __init__ (self, name, born ): self.name = name self.born = born @property def age (self ): return datetime.now().year - self.born person = Person("Babb Chen" , 1994 ) print(person.__dict__) print(json.dumps(person.__dict__)) def seriealize_person (obj ): if isinstance (obj, Person): return { "name" : obj.name, "age" : obj.age } raise TypeError("Object not serializable" ) print(json.dumps(person, default=seriealize_person))
# json deserialize1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 from datetime import datetimefrom fractions import Fractionimport jsonfrom pprint import pprintdef custom_decoder (arg ): print("decoding:" , arg, type (arg)) return arg s = """ { "a": 1, "b": 2, "c": { "c.1": 1, "c.2": 2, "c.3": { "c.3.1": 1, "c.3.2": 2 } } } """ d = json.loads(s, object_hook=custom_decoder) print(d) def custom_decoder (arg ): ret_value = arg if "objecttype" in arg: if arg["objecttype" ] == "datetime" : ret_value = datetime.strptime(arg["value" ], "%Y-%m-%dT%H:%M:%S" ) elif arg["objecttype" ] == "fraction" : ret_value = Fraction(arg["numerator" ], arg["denominator" ]) return ret_value s = """ { "cake": "yummy chocolate cake", "myShare": { "objecttype": "fraction", "numerator": 1, "denominator": 8 }, "eaten": { "at": { "objecttype": "datetime", "value": "2018-10-21T21:30:00" }, "time_taken": "30 seconds" } } """ d = json.loads(s, object_hook=custom_decoder) pprint(d)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 import jsondef float_handler (arg ): print("float handler" , type (arg), arg) return float (arg) def int_handler (arg ): print("int handler" , type (arg), arg) return int (arg) def const_handler (arg ): print("const handler" , type (arg), arg) return None def obj_hook (arg ): print("obj hook" , type (arg), arg) return arg def obj_pairs_hook (arg ): print("obj pairs hook" , type (arg), arg) return arg s = """ { "a": [1, 2, 3, 4, 5], "b": 100, "c": 10.5, "d": NaN, "e": null, "f": "python" } """ d = json.loads( s, object_hook=obj_hook, parse_float=float_handler, parse_int=int_handler, parse_constant=const_handler, ) print(d) d = json.loads( s, object_pairs_hook=obj_pairs_hook, parse_float=float_handler, parse_int=int_handler, parse_constant=const_handler, ) print(d)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import reimport jsonfrom decimal import Decimalfrom pprint import pprintclass Point : def __init__ (self, x, y ): self.x = x self.y = y def __repr__ (self ): return f"Point(x={self.x} , y={self.y} )" s = """ { "a": 100, "b": 0.5, "rectangle": { "corners": { "b_left": {"_type": "point", "x": -1, "y": -1}, "b_right": {"_type": "point", "x": 1, "y": -1}, "t_left": {"_type": "point", "x": -1, "y": 1}, "t_right": {"_type": "point", "x": 1, "y": 1} }, "rotate": {"_type" : "point", "x": 0, "y": 0}, "interior_pts": [ {"_type": "point", "x": 0, "y": 0}, {"_type": "point", "x": 0.5, "y": 0.5} ] } } """ class CustomDecoder (json.JSONDecoder ): base_decoder = json.JSONDecoder(parse_float=Decimal) def decode (self, s ): obj = self.base_decoder.decode(s) pattern = r'"_type"\s*:\s*"point"' if re.search(pattern, s): obj = self.make_pts(obj) return obj def make_pts (self, obj ): if isinstance (obj, dict ): if "_type" in obj and obj["_type" ] == "point" : obj = Point(obj["x" ], obj["y" ]) else : for key, value in obj.items(): obj[key] = self.make_pts(value) elif isinstance (obj, list ): for index, item in enumerate (obj): obj[index] = self.make_pts(item) return obj d = json.loads(s, cls=CustomDecoder) pprint(d) pts = d["rectangle" ]["interior_pts" ][1 ] print(type (pts.x), type (pts.y))
# jsonschema1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import jsonimport jsonschemaperson_schema = { "type" : "object" , "properties" : { "firstName" : {"type" : "string" , "minLength" : 1 }, "middleInitial" : {"type" : "string" , "minLength" : 1 , "maxLength" : 1 }, "lastName" : {"type" : "string" , "minLength" : 1 }, "age" : {"type" : "integer" , "minimum" : 0 }, "eyeColor" : { "type" : "string" , "enum" : [ "amber" , "blue" , "brown" , "gray" , "green" , "hazel" , "red" , "violet" , ], }, }, "required" : ["firstName" , "lastName" ], } json_doc = """ { "firstName": "John", "middleInitial": 100, "lastName": "Cleese", "age": "Unknown" } """ try : jsonschema.validate(json.loads(json_doc), person_schema) except json.JSONDecodeError as e: print(f"Invalid JSON: {e} " ) except jsonschema.exceptions.ValidationError as e: print(f"Validition JSON error: {e} " ) else : print("JSON is valid and conforms to schema" ) for error in jsonschema.Draft4Validator(person_schema).iter_errors( json.loads(json_doc) ): print(error, end="\n------------------\n" )
1 2 3 4 5 6 7 8 9 import xml.dom.minidom as xdomfrom pathlib import Pathwork_dir = r'C:\Users\11435\Desktop\practice\python\formatxml\xmlfiles' paths = Path(work_dir).glob('**/*.xml' ) for path in paths: prettied = xdom.parseString(path.read_text()).toprettyxml() path.write_text(pettied)
# nested XML to pandas dataframedata.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <data > <record > <name > Babb</name > <age > 30</age > <address > <city > New York</city > <state > NY</state > </address > </record > <record > <name > John</name > <age > 25</age > <address > <city > New York</city > <state > NY</state > </address > </record > </data >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import pandas as pdimport xml.etree.ElementTree as ETtree = ET.parse('data.xml' ) root = tree.getroot() def parse_element (element, item ): if len (list (element)) == 0 : item[element.tag] = element.text else : for child in list (element): parse_element(child, item) data = [] for child in root: item = {} parse_element(child, item) data.append(item) print(data) df = pd.DataFrame(data) print(df)
Use pandas.read_xml iterparse
iterparse dict, optionaliterparse = {"row_element": ["child_elem", "attr", "grandchild_elem"]
1 2 3 4 5 6 7 8 9 10 11 12 iterparse_config = { "record" : ["name" , "age" , "city" , "state" ] } df = pd.read_xml('data.xml' , iterparse=iterparse_config) print(df)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from io import BytesIO, StringIOimport pandas as pdxml_data = ''' <data> <record> <name>Babb</name> <age>30</age> <address> <city>New York</city> <state>NY</state> </address> </record> <record> <name>John</name> <age>25</age> <address> <city>New York</city> <state>NY</state> </address> </record> </data> ''' iterparse_config = { "record" : ["name" , "age" , "city" , "state" ] } df = pd.read_xml(BytesIO(xml_data.encode()), iterparse=iterparse_config) df = pd.read_xml(BytesIO(xml_data.encode()), iterparse=iterparse_config, parser='etree' ) df = pd.read_xml(StringIO(xml_data), iterparse=iterparse_config, parser='etree' ) print(df)
# fake large csv1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import pandas as pdfrom faker import Fakerdef generate_large_csv (num_rows, filename ): fake = Faker() data = [] for _ in range (num_rows): data.append( [ fake.uuid4(), fake.name(), fake.email(), fake.date_between(start_date="-5y" , end_date="today" ), fake.country(), fake.random_int(min =1000 , max =100000 ), ] ) df = pd.DataFrame(data, columns=["id" , "name" , "email" , "date" , "country" , "value" ]) df.to_csv(filename, index=False ) print(f"Generated {num_rows} rows and saved to {filename} " ) if __name__ == "__main__" : generate_large_csv(100_000 , "large_data.csv" )
# csv to database1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pandas as pdfrom sqlalchemy import create_engineengine = create_engine('oracle+cx_oracle://username:pass@ip:port/instance' ) df = pd.read_csv("test.csv" , sep=',' ) df.to_sql('test' , engine, index= False ) print("Write to Oracle successfully!" )
# quit python Interactive Shellpython Interactive Shell 通过 EOF (End Of File) 退出,python 在 parse stdin 的时候判断是否是 EOF。
Mac/Linux 按 Ctrl + D 退出,Window 先按 Ctrl + Z 然后按 Enter 退出。
1 2 3 python 3.9.6 (tags/v3.9.6:db3ff76, Jun 28 2021, 15:26:21) [MSC v.1929 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. > >> ^Z
# Jupyter notebook to markdownjupyter nbconvert -h
jupyter nbconvert mynotebook.ipynb --to markdown
# prettytable1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from prettytable import PrettyTablerow = PrettyTable(["城市" ,"总访问量" , "失败量" , "慢速量" ,"失败率" ,"慢速率" ]) row.align["城市" ] = "l" row.padding_width = 1 retrow = [['郑州' ,241 ,1 ,2 ,0.41 ,0.83 ],['灵宝' ,56 ,0 ,1 ,0.0 ,1.79 ]] for r in retrow: row.add_row(r) with open ('D:/study/fragment/mytable' ,'w' ,encoding='utf-8' ) as hfile: hfile.write(str (row)) hfile.close()
# tqdm1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from tqdm import tqdmimport seaborn as snsdf = sns.load_dataset("iris" ) print(df.head()) tqdm.pandas(desc="Processing iris" ) df.petal_width.progress_apply(lambda x: x * 2 )
# dotenv to enviroment1 2 3 4 5 6 7 8 9 10 import osfrom dotenv import load_dotenvload_dotenv() db_user = os.getenv("DB_USER" ) db_password = os.getenv("DB_PASSWORD" ) print(f"{db_user=} " ) print(f"{db_password=} " )
.env
1 2 DB_USER = 'fake_username' DB_PASSWORD = 'fake_password'
# Quiz# Why judgement None must use ‘is’ in python?1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 a = None if not a: print('None' ) if a == None : print('None' ) if a is None : print('None' )
第一种方式在 [], {}, set(), None, False 这几种情况下都符合,用户自定义类型也可以通过重载 __bool__ 定义什么时候是 True/False.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 lst = [[], {}, set (), None , False ] for a in lst: if not a: print(a) class MyDataStructure : def __bool__ (self ): return False d = MyDataStructure() if not d: print("It's None" )
第二种方式,用户自定义类型可以通过重载 eq 定义什么时候是 True/False.
1 2 3 4 5 6 7 8 class MyDataStructure : def __eq__ (self, other ): return True d = MyDataStructure() if d == None : print(d)
# Why list comprehensions multi lambdas ouput same result?1 2 3 4 funcs = [lambda x: x**i for i in range (6 )] print(funcs[0 ](10 ), funcs[1 ](10 ), funcs[2 ](10 ))
Internal Mechanics of List Comprehensions
1 2 3 4 5 6 7 8 9 10 11 12 import discompiled_code = compile ('[i**2 for i in (1, 2, 3)]' , filename='' , mode='eval' ) dis.dis(compiled_code)
As you can see, in step 4, python created a function ( MAKE_FUNCTION ), called it ( CALL_FUNCTION ), and then returned the result ( RETURN_VALUE ) in the last step.
So, comprehensions will behave like functions in terms of scope . They have local scope, and can access global and nonlocal scopes too. And nested comprehensions will also behave like nested functions and closures.
In funcs = [lambda x: x**i for i in range(6)] the i was a local variable in the list comprehension, and each function created in the comprehension is referencing the same i - it is local to the comprehension, and each lambda is therefore a closure with (the same) free variable i . And by the time the comprehension has finished running, i had a value of 5
The above code is like below, except the i is global variable.
1 2 3 4 5 6 7 8 funcs = [] for i in range (6 ): funcs.append(lambda x: x**i) print(i, 'i' in globals ()) print(funcs[0 ](10 ), funcs[1 ](10 ), funcs[2 ](10 ))
Can we somehow fix this problem?
Yes, and it relies on default values and when default values are calculated and stored with the function definition. Recall thatd efault values are evaluated and stored with the function’s definition when the function is being created (i.e. compiled) . Right now we are running into a problem because the free variable i is being evauated inside each function’s body at run time .
So, we can fix this by making each current value of i a paramer default of each lambda - this will get evaluated at the functions creation time - i.e. at each loop iteration:
1 2 3 4 5 funcs = [lambda x, pow =i: x**pow for i in range (6 )] print(funcs[0 ](10 ), funcs[1 ](10 ), funcs[2 ](10 ))
# The difference of iterable and iterator?iterator must be iterable,but iterable not must be iterator.
# iterator
implement __iter__ and __next__ method.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Cities : def __init__ (self ): self._cities = ['Paris' , 'Berlin' , 'Rome' , 'Madrid' , 'London' ] self._index = 0 def __iter__ (self ): return self def __next__ (self ): if self._index >= len (self._cities): raise StopIteration else : item = self._cities[self._index] self._index += 1 return item
yield generator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import mathdef factorials (n ): for i in range (n): yield math.factorial(i) for num in factorials(5 ): print(num) f = factorials(5 ) print('__iter__' in dir (f), '__next__' in dir (f))
# iterable
implement __getitem__ method
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Fib : def __init__ (self, n ): self._n = n def __len__ (self ): return self._n def __getitem__ (self, s ): if isinstance (s, int ): if s < 0 : s = self._n + s if s < 0 or s > self._n - 1 : raise IndexError return self._fib(s) else : idx = s.indices(self._n) rng = range (idx[0 ], idx[1 ], idx[2 ]) return [self._fib(n) for n in rng] @staticmethod @lru_cache(2 **32 def _fib (n ): if n < 2 : return 1 else : return fib(n-1 ) + fib(n-2 ) f = Fib(10 ) for item in f: print(item)
implement __iter__ method and the method return iterator, but not implement __next__ .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Cities : def __init__ (self ): self._cities = ['New York' , 'Newark' , 'New Delhi' , 'Newcastle' ] def __len__ (self ): return len (self._cities) def __getitem__ (self, s ): print('getting item...' ) return self._cities[s] def __iter__ (self ): print('Calling Cities instance __iter__' ) return self.CityIterator(self) class CityIterator : def __init__ (self, city_obj ): print('Calling CityIterator __init__' ) self._city_obj = city_obj self._index = 0 def __iter__ (self ): print('Calling CitiyIterator instance __iter__' ) return self def __next__ (self ): print('Calling __next__' ) if self._index >= len (self._city_obj): raise StopIteration else : item = self._city_obj._cities[self._index] self._index += 1 return item