转载: Data structure - R introduction documentation
R is an object-oriented language: an object in R is anything (constants, data structures, functions, graphs) that can be assigned to a variable:
- Data Objects: used to store real or complex numerical values, logical values or characters. These objects are always vectors: there are no scalars in R.
- Language Objects: functions, expressions
# Data structure types
-
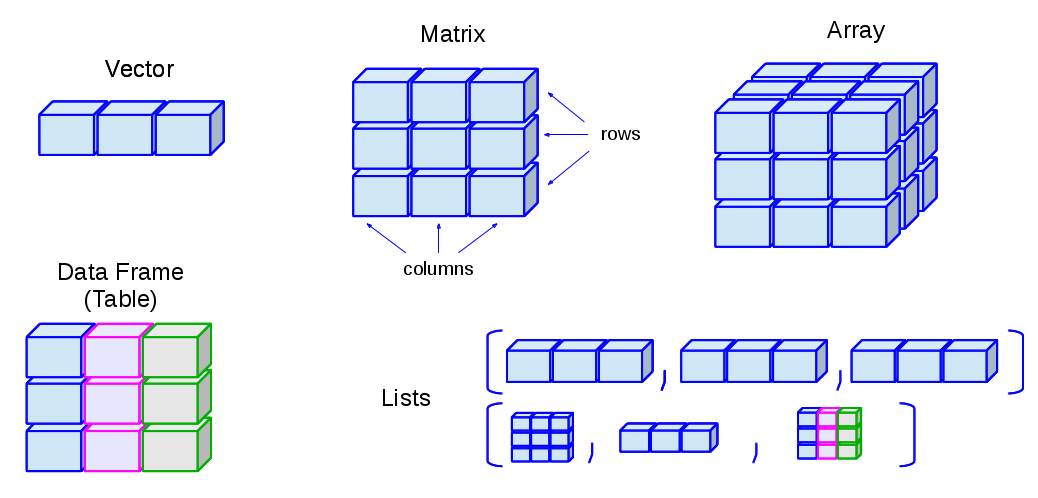
Vectors: one-dimensional arrays used to store collection data of the same mode
- Numeric Vectors (mode: numeric)
-
Complex Vectors (mode: complex)
- Logical Vectors (model: logical)
- Character Vector or text strings (mode: character)
-
Matrices: two-dimensional arrays to store collections of data of the same mode. They are accessed by two integer indices.
-
Arrays: similar to matrices but they can be multi-dimensional (more than two dimensions)
-
Factors: vectors of categorical variables designed to group the components of another vector with the same size
-
Lists: ordered collection of objects, where the elements can be of different types
-
Data Frames: generalization of matrices where different columns can store different mode data.
-
Functions: objects created by the user and reused to make specific operations.
# Vectors
# Numeric Vectors
There are several ways to assign values to a variable:
1 | > a <- 1.7 # assign a value to a vector with only one element (~ scalar) |
To show the values:
1 | > a # show the value in the screen (not valid in scripts) |
To generate a vector with several numeric values:
1 | > a <- c(10, 11, 15, 19) # assign four values to a vector using the concatenate command c() |
The operations are always done over all the elements of the numeric array:
1 | > a*a # evaluate the square value of every element in the vector |
To generate a sequence:
1 | > 2:10 # generate a sequence from n1=2 to n2=10 using n1:n2 |
To generate repetitions:
1 | > a <- 1:3; b <- rep(a, times=3); c <- rep(a, each=3) # command rep() |
In the previous example we have run three commands in the same line. They have been separated by a ‘;’.
The content of the three variables is now:
1 | > a |
The recycling rule: vectors of different sizes can be combined, as far as the length of the longer vector is a multiple of the shorter vector’s length (otherwise a warning is issued, although the operation is carried out):
1 | > a+c # proper dimensions |
If we need to know which are the objects that are currently defined, we can list them:
1 | > ls() |
Undesired objects can be deleted using rm() function:
1 | > rm(a,c) # remove objects 'a' and 'b' |
In order to remove everything in the working environment:
1 | > rm(list=ls()) # Use this with caution |
# Logical Vectors
1 | > a <- seq(1:10) # generate a sequence |
# Character Vectors
1 | > a <- "This is an example" # generate a character vector |
We can concatenate vectors after converting them into character vectors:
1 | > x <- 1.5 |
# Matrices
A matrix is a bi-dimensional collection of data:
1 | > a <- matrix(1:12, nrow=3, ncol=4) # define a matrix with 3 rows and 4 columns |
The elements of vectors and matrices are recycled when it is required by the involved dimensions:
1 | > a <- matrix(1:8, nrow=4, ncol=4) # create a matrix with 4 rows and 4 columns |
# Arrays
They are similar to the matrices although they can have 2 o more dimensions.
1 | > z <- array(1:24, dim=c(2,3,4)) |
# Factors
Factors are vectors that contain categorical information useful to group the values of other vectors of the same size. Let’s see an example:
1 | > bv <- c(0.92,0.97,0.87,0.91,0.92,1.04,0.91,0.94,0.96, |
If additional information is available (for instance, the morphological type of the galaxies) we can create a factor containing the galaxy types:
1 | > morfo <- c("Sab","E","Sab","S0","E","E","S0","S0","E", |
We could use this additional information to perform an statistical analysis segregating the data according to these types. This will be covered lately in the Functions section.
# Lists
Lists are ordered collections of objects, where the elements can be of a different type (a list can be a combination of matrices, vectors, other lists, etc.) They are created using the list() function:
1 | > gal <- list(name="NGC3379", morf="E", T.RC3=-5, colours=c(0.53,0.96)) |
New elements can be added in a simple way, just defining them:
1 | > gal$radio <- TRUE # add a boolean element |
Lists can be concatenated to generate bigger lists. If we have list1 , list2 , list3 , we can create a unique list which is the result of the union of these three lists:
1 | > list123 <- c(list1, list2, list3) |
As the elements in a list can be R objects of a different type:
- Lists are extremely versatile since they can store every type of information (good)
- Lists can be converted in objects with a rather complex structure (bad). A list can contain several elements which are vectors of different length, which is similar to having a table where the columns have a different number of rows.
The ideal situation is to take advantage of the list versatility but preventing them from growing with a very complex structure. This is why R has defined a new type of data which fulfils both requirements: a Data Frame.
# Data Frames (Tables)
A Data Frame is an special type of list very useful for the statistical work. There are some restrictions to guarantee that they can be used for this statistical purpose.
Among other restrictions, a Data Frame must verify that:
- List components must be vectors (numeric, character or logical vectors), factors, numeric matrices or other data frames.
- Vectors, which are the variables in the data frame, must be of the same length.
Warning
In a data frame, character vectors are automatically converted into factors, and the number of levels can be determined as the number of different values in such a vector. This default behaviour can be modified with the options(stringsAsFactors = FALSE) command.
Basically, in a Data Frame all the information is displayed as a table where the columns have the same number of rows and can contain different type objects (numbers, characters, …).
Data Frames can be created using the data.frame() function. Let’s see how to define a data frame with two elements, a numeric vector and a character vector (note that both must be same length vectors):
1 | > options(stringsAsFactors = FALSE) |
However the most common way of defining a data frame is reading the data stored in a file. We will see later how to do it using read.table() function.
# Factors and Tables
It is frequently useful (for instance, for table creation) to be able to generate factors from a numeric continuum variable. To do so, we can use the cut command. Its parameter breaks defines how the data are divided. If breaks is a number, this is used as the number of (same length) intervals:
1 | > bv <- c(0.92,0.97,0.87,0.91,0.92,1.04,0.91,0.94,0.96, |
If breaks is a vector, its values are used as the limits of the intervals:
1 | > ffbv <- cut(bv,breaks=c(0.80,0.90,1.00,1.10)) |
If we want just an approximate number of intervals, but with equally spaced round values, we can use the pretty() function (that not always returns the specified number of intervals!):
1 | > fffbv <- cut(bv,pretty(bv,3)) # ask for 3 'pretty' intervals |
We can also use a quantile division:
1 | > ffffbv <- cut(bv,quantile(bv,(0:4)/4)) # ask for the 4 quantiles |
Warning
The last two groupings exclude the value 0.85 which is one of our data values.
Factors can be used to build multi-dimensional tables. Let’s see how. First of all, we will define the data (that in a real case would be read from a data file):
1 | > heights <- c(1.64,1.76,1.79,1.65,1.68,1.65,1.86,1.82,1.73, |
For each one of these variables we can generate factors:
1 | > fheights <- cut(heights,c(1.50,1.60,1.70,1.80,1.90)) # factor for 'heights' |
Table generation is now straightforward using these factors. We can, for instance, generate bi-dimensional tables:
1 | > ta <- table(fheights, fweights) # table for 'heights' vs. 'weights' |
Marginal frequencies can also be included:
1 | > addmargins(ta) |
Or we can work with the relative frequencies;
1 | > tta <- prop.table(ta) |
We can also generate tridimensional tables. Following the previous example, we can examine the same bi-dimensional table for each age interval:
1 | > table(fheights, fweights, fages) |
# Matrices and Tables
We can easily generate 2D tables from matrices:
1 | > mtab <- matrix(c(30,12,47,58,25,32), ncol=2, byrow=TRUE) # create a matrix filled by rows |
However, mtab is not a true R table. To transform it into a true table we can use:
1 | > rtab <- as.table(mtab) |
In addition to the functions to calculate marginal distributions ( margin.table ), frequencies ( prop.table ), etc., the command summary returns the x^2
test for the independence of the factors:
1 | > summary(rtab) |
The same command returns a different result when it is applied to a matrix type object:
1 | > summary(mtab) |
# Functions
These are objects that can be created by the user and then re-used to make specific operations.
For example, we can define a function to calculate the standard deviation:
1 | > stddev <- function(x) { # user-defined function 'stddev' |
Functions can be defined inside other functions (nested) and can also be passed as arguments to other functions. The value returned by a function is the result of the last expression evaluated in the body of the function or the value grabbed by the return command.
R functions arguments can have default values or can be missing. Arguments can be matched by name or position:
1 | > mynumbers <- c(1, 2, 3, 4, 5) |
# Looping Functions
There are special R functions that can be used to repeat instructions in the command line and facilitate the programming process:
- lapply: evaluate a function for each element of a list
- sapply: evaluate a function for each element of a list simplifying the result
- apply: Apply a function over the margins of an array (usually to apply a function to the rows/columns in a matrix)
- tapply: Apply a function over subsets of a vector (for example defined with a factor)
- mapply: Multivariate version of lapply
Let’s see how to apply these functions to the previous example with the galaxy colours:
1 | > bv.vec <- c(0.92,0.97,0.87, 0.91,0.92,1.04,0.91,0.94,0.96, |
lapply
1 | > bv.list <- list(colsSab=c(0.92,0.87,0.90,0.86), |
sapply
1 | > sapply(bv.list, mean) # simplified version of 'lapply' |
tapply
1 | > fmorfo <- factor(morfo) # create factor |
apply
1 | > a <- matrix(1:12, nrow=3, ncol=4) # define a matrix with 3 rows and 4 columns |
# Special Values
It is useful to define some values as _ Not Available_ (NA):
1 | > a <- c(0:2, NA, NA, 5:7) # define vector with NA values |
We can carry out mathematical operations:
1 | > a*a # calculate the square of 'a' |
We can check whether there is any undefined value:
1 | > unavail <- is.na(a) # use of is.na() function |
Sometimes calculations end up in values with no mathematical sense:
1 | > a <- log(-1) |
To check whether we have Infinite values or Not-a-Number values:
1 | > is.infinite(d) # is there any Infinite value? |
Main R functions ( mean , var , sum , min , max ,…) accept an argument called na.rm that can be set as TRUE or FALSE to remove (or not) the unavailable data.
1 | > a <- c(0:2, NA, NA, 5:7) # define vector 'a' with Not-Available data |
# Subsetting
Several R operators can be used to extract subsets (slices) from R objects:
- [ can be used to extract one or more elements of an R object. It always returns an object of the same class
- [[ can be used to extract a single element from a data frame or a list. The class of the extracted element can be different from the original object.
- $ can be used to extract named elements from a data frame or a list.
For Numeric Vectors:
1 | > a <- 1:15 # generate a sequence |
For Character Vectors:
1 | > a <- c("A", "B", "C", "C", "D", "E") |
For Matrices, elements are accessed through two integer indices:
Note
The agreement to establish the indices order a[i,j] is the same than the one used in Math for the matrix coefficients a ij
1 | > a <- matrix(1:12, nrow=3, ncol=4) # define a matrix with 3 rows and 4 columns |
Note
By default, subsetting a single element or a single row or a single column returns a vector, not a matrix (this can be changed using drop=FALSE )
1 | > a[2,3, drop=FALSE] # so as not to 'drop' the dimension |
The access to the matrix elements can be done with the indices stored in other auxiliary matrices:
1 | > ind <- matrix(c(1:3,3:1), nrow=3, ncol=2) # auxiliary matrix for the indices i,j |
For lists:
The list components can be accessed using the three operators mentioned above ([, [[ and $):
1 | > gal <- list(name="NGC3379", morf="E", colours=c(0.53,0.96)) |
To extract multiple elements of a list, single bracket is mandatory:
1 | > gal <- list(name="NGC3379", morf="E", colours=c(0.53,0.96)) |
For computed indices the [[ and [ operators can be used. The $ operator can only be used with literal names:
1 | > gal <- list(name="NGC3379", morf="E", colours=c(0.53,0.96)) |
To recursively extract an element:
1 | > gal <- list(name="NGC3379", morf="E", colours=c(0.53,0.96)) |
Elements can be extracted using partial matching with the [[ and $ operators:
1 | > gal <- list(name="NGC3379", morf="E", colours=c(0.53,0.96)) |
For Data Frames (Tables), the operators used for slicing are the same than those used for lists:
1 | > airquality # data frame in R library |
For Character Strings the access to their elements is done in a different way:
1 | > a <- "This is an example of a text string" # define a character string |
# Removing NA values
We can remove Not Available values in a simple way using subsetting:
1 | > a <- c(0:2, NA, NA, 5:7) # define vector with NA values |
To take the subset of multiple vectors avoiding the missing values:
1 | > a <- c( 1, 2, 3, NA, 5, NA, 7) |
We can also use the function complete.cases to remove missing values from data frames:
1 | > airquality # data frame in R library |