# Excel to Oracle
**pandas.DataFrame.to_sql¶**
DataFrame.to_sql(*self*, *name*, *con*, *schema=None*, *if_exists='fail'*, *index=True*, *index_label=None*, *chunksize=None*, *dtype=None*, *method=None*)
Write records stored in a DataFrame to a SQL database.
Databases supported by SQLAlchemy [1] are supported. Tables can be newly created, appended to, or overwritten.
| param | mean |
|---|---|
| name : string | Name of SQL table. |
| name : stringName of SQL table.con : sqlalchemy.engine.Engine or sqlite3.Connection | Using SQLAlchemy makes it possible to use any DB supported by that library. Legacy support is provided for sqlite3.Connection objects. |
| schema : string, optional | Specify the schema (if database flavor supports this). If None, use default schema. |
| if_exists : {‘fail’, ‘replace’, ‘append’}, default ‘fail’ | How to behave if the table already exists.fail: Raise a ValueError. replace: Drop the table before inserting new values. append: Insert new values to the existing table. |
| index : bool, default True | Write DataFrame index as a column. Uses index_label as the column name in the table. |
| index_label : string or sequence, default None | Column label for index column(s). If None is given (default) and index is True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex. |
| chunksize : int, optional | Rows will be written in batches of this size at a time. By default, all rows will be written at once. |
| dtype : dict, optional | Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types or strings for the sqlite3 legacy mode. |
| method : {None, ‘multi’, callable}, default None | Controls the SQL insertion clause used: None : Uses standard SQL INSERT clause (one per row). ‘multi’: Pass multiple values in a single INSERT clause. callable with signature (pd_table, conn, keys, data_iter) . |
1 | from sqlalchemy import create_engine |
# CSV to Excel
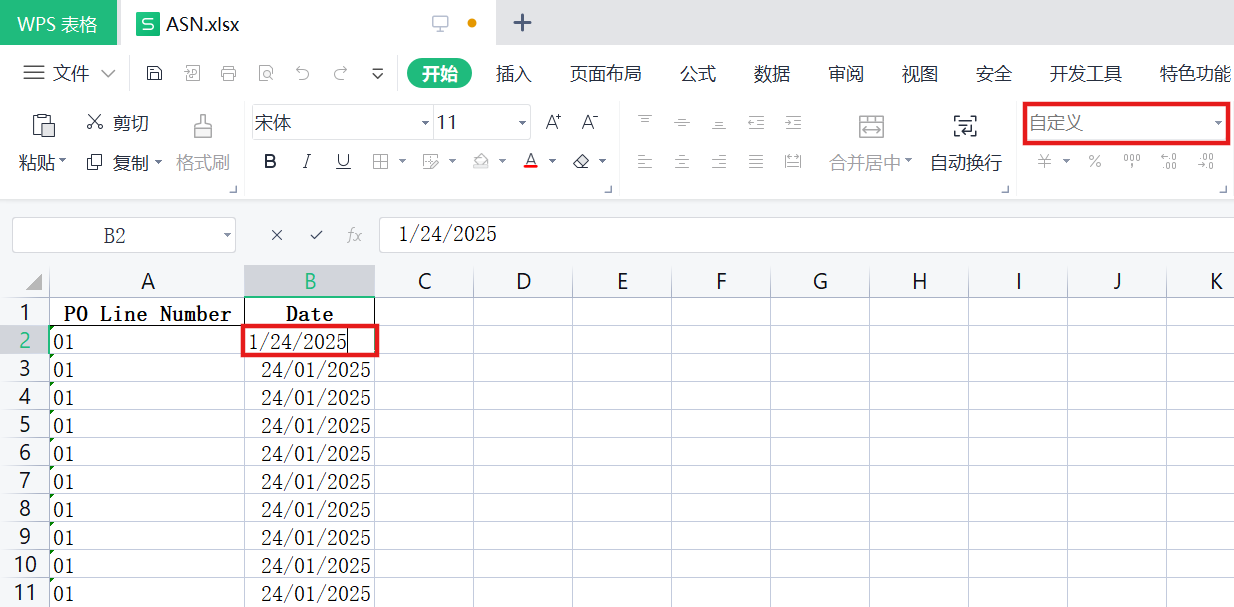
Convert CSV to Excel, and meet the following requirements.
- Keep the leading zero.
- The date format in Excel is
DD/MM/YYYY.
1 | PO Line Number,Date |
1 | import pandas as pd |
# BUG: ExcelWriter set_column with num_format datetime doesn’t work (but it works for xlsxwriter)
# Reproducible Example
1 | from datetime import datetime |
# Issue Description
I created an Excel sheet using pd.to_excel() . The data contains one column with a float number and one column with a datetime.datetime object.
Then, I want to set the column type using the num_format parameter in set_column .
This works for the float value, which I want in the percentage format.
However, it does not work for the datetime value. The value is in the wrong format “01.01.2020 00:00:00” (German date). The value in the Excel file is in the same wrong format, whether I run set_column() for the date column or not.
I have tried to circle in the problem by trying other variations, which turns out that they do work. However, those would be only workarounds for our use case.
- Using the parameter
datetime_format='dd.mm.yyyy'in thepd.ExcelWriterconstructor puts the date into the right format. - Instead of writing the sheet from a DataFrame, using the
xlsxwriterfunctions works fine:
1 | import xlsxwriter |
# Expected Behavior
The value is in the format “01.01.2020” when using set_column with pd.ExcelWriter .
# Why
set_column does not change the format; it changes the default format:
The cell_format parameter will be applied to any cells in the column that don’t have a format.
Since pandas is setting the format for date cells, it has no effect. As far as I can tell there is no easy way to overwrite an existing format with xlsxwriter. The best resolution I see for this within pandas is to use datetime_format as you mentioned.